Introduction
In the ever-evolving field of artificial intelligence(AI) and generative AI, many large language models(LLM) are still working with singular modality. The meaning of singular modality is that they can work with single type of data, whether its text, image or audio. You can convert text into text or audio into audio using these single modal LLMs.
But what if we can communicate with these modals in multiple modalities like we do on a messaging applications like whatsapp, discord or slack then you can do it with multimodal LLMs. Multimodal LLMs have emerged as a groundbreaking advancement by representing the combination of various modalities to generate content in a more precise and holistic manner.
What is multimodal LLM?
A multimodal Language model is an advanced version of artificial intelligence model that is capable of generating and processing multiple modalities or forms of data. Unlike traditional language models that primarily focus on textual data, multimodal LLMs have the ability to understand and generate content from diverse sources such as text, images, audio, and even video.
In simpler terms, a multimodal LLM is an AI system that can perceive and create content that involves more than just text. It can understand and generate information that combines text with visual elements like images or diagrams, audio recordings, or even videos.
Understanding multimodal learning
Multimodal learning refers to the process of training machine learning models on data that combines multiple modalities or sources of information. Instead of relying on a single input modality, these models are designed to learn from and integrate information from various modalities simultaneously.
Importance of multimodal learning
Imagine having a friend who can understand not just your words but can also understand images, audio and videos which you send to him and it will make the conversation more fun. The main problem with older singular model LLMs was that they were not able to understand more than one modality at a time and sometimes it becomes hard to properly explain your problem or output for both LLM and you too 😅.
Here is why multimodal LLMs are important:
- Filling the Gap Between Text and Reality: Text alone can be hard to explain or understand sometimes and this is where multimodal LLMs makes it easy. For example, you want to make one project and want to know some suggestions on review on architecture of that project then you can easily provide the image of flow diagram of architecture and it can provide reviews on it and also it can create updated architecture too at the same time.
- More Creativity: Multimodal LLMs have increased the creative capability of normal LLMs by providing multiple modalities at the same time. They can generate videos based on text or can create story from an image
- Improving Human-Computer Interaction: Multimodal LLMs have increased the quality of conversation by making it more realistic with multiple modalities. Its just same as you are texting your friend
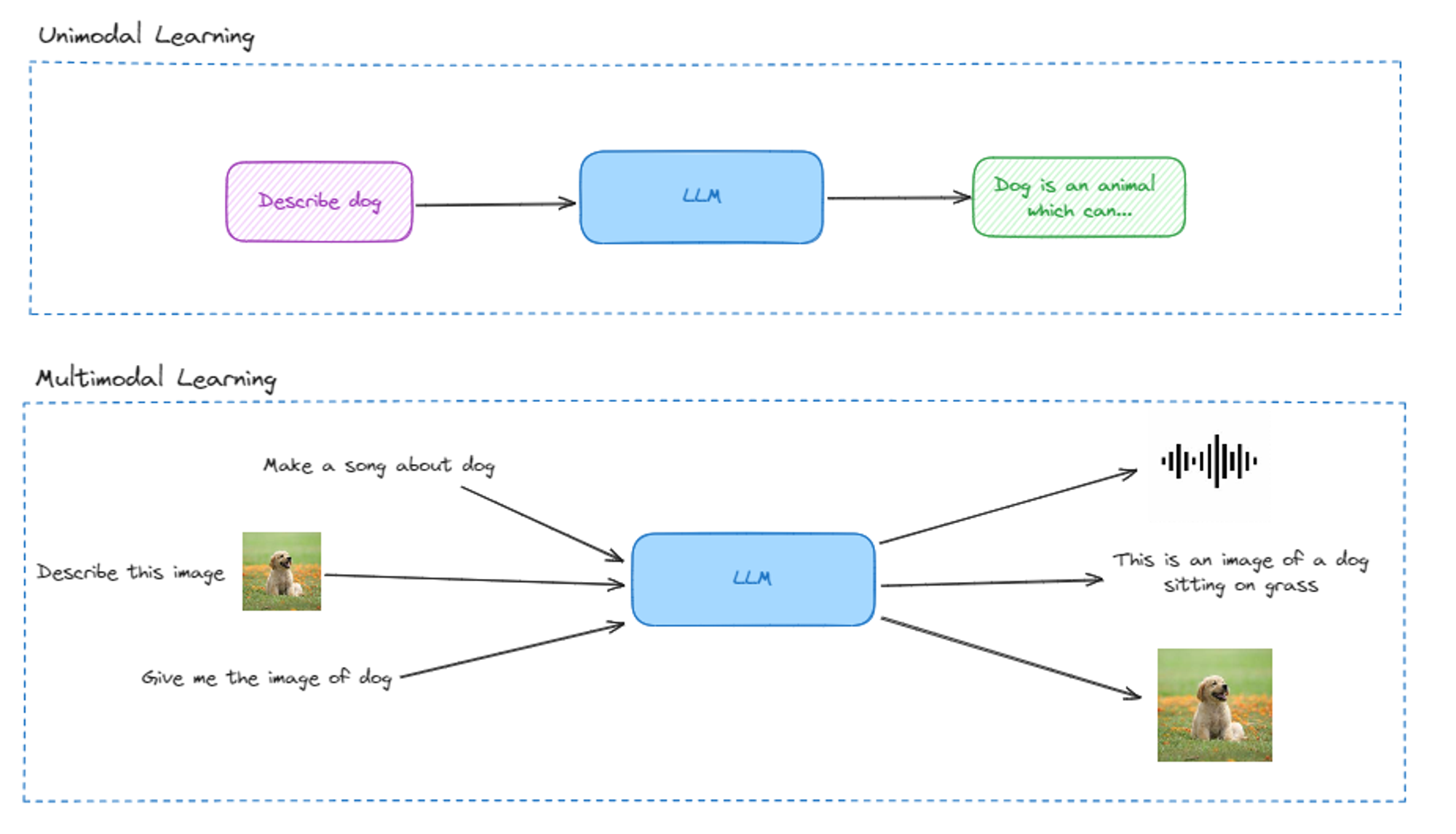
Comparison with unimodal learning
In unimodal learning, every model is trained on a dataset of data with singular modality. On other side, multimodal models are trained on multiple modality or form of data which makes them more precise and creative.
Unimodal learning is very useful in classification tasks such as image recognition which can classify images, detect objects inside a image or classify different tasks. However in complex problems, such as disease prediction, only the image is not sufficient to accurately predict the type of disease. In such cases multimodal learning helps us to increase the understanding of disease.
Here is the comparison diagram for unimodal learning vs multimodal learning:
Description of different modalities
Different data modes are text, image, audio, tabular data, etc. One data mode can be represented or approximated in another data mode. For example:
- Text: Text is the one of the most common mode or form of data in LLMs. They can process and understand the text which allows them to analyze data, generate text descriptions, translate languages and answer your question in informative way
- Images: Images can be converted into vector embeddings or any other format so that LLMs can understand them and find objects in an image, generate images or find similar images for a given image
- Audio: Audio files can be processed by analyzing audio data, recognizing speech patterns, understand the sentiment behind audio or even convert the audio into text or vice versa.
- Video: By combining image and audio processing, multimodal LLMs can analyze videos by breaking down a video into frames and audio tracks, analyze content of each frame, find object in video or generate summaries of video content
Components of multimodal LLM
Multimodal LLMs are complex systems with 5 main components working together to understand and process information of different modalities.
Here is what architecture of multimodal LLM looks like 👀

Let’s learn about each component in detail 🚀
Modality Encoders
First of all, we need to convert data of every modality in a form such that LLMs can understand it. We know that unimodal LLMs also use tokenizers or encoders to encode the data so that it can be passed to transformer. In a same way, here we need multiple encoders for each form of data which is knows as modality encoders.
The modality encoders is crucial part of multimodal language model. It is responsible for processing and encoding data from different modalities like text, image, audio and video. There are different encoders for each modality type, such as text encoder or audio encoder.
Each modality encoder is designed to extract specific information from its corresponding input data. For example, the text encoder might extract semantic representations from text, while the image encoder extracts visual features from images.
Input Projector
Once we got all the encoded data from individual modalities, we need to combine all that data in a single format. Input projector takes the encoded representations of data and combines them in a unified format.
This is typically done by concatenating or projecting the modality-specific representations (output of modality encoders) into a shared embedding space. This allows the LLM to consider all the information together and can work with different modalities of data at the same time. This representation is then used by LLM backbone.
LLM Backbone
LLM backbone is the core component of multimodal LLM. It is a large language model trained on a huge amount of data, similar to the models used in text only tasks. It is responsible to get the representation of data from input projector and generate outputs like text descriptions, summaries or any other creative content.
These LLMs are trained to work with data from different modalities like image or audio through the combined input representation.
Output Projector
Once LLM backbone completes the generation task, we have to convert the encoded data back into desired format or the desired modality if needed. Output projector takes the output of LLM and converts it back to desired format for the target task.
For example, if the task is to caption an image then it will convert LLM’s output into sequence of words describing the image. Output projector can also output in different modalities same as modality encoders.
Modality Generator
For some multimodal LLMs, you might need a modality generator to generate the output data in different modalities based on your target task. For example, if the task is to generate an audio then modality generator will take the output from LLM backbone and generate corresponding audio.
The modality generator can be implemented using various techniques such as generative adversarial networks (GANs), variational autoencoders (VAEs) or diffusion models depending on your target modality of task.
Training multimodal LLMs
There are several ways to train a multimodal LLM and many modals are trained on their own approach. In this blog, we will focus on 3 major and popular multimodal models and see how they are trained.
CLIP
CLIP stands for Contrastive Language-Image Pre-training which was introduced in 2021 by researchers at OpenAI in which they introduced a zero shot inference technique for image embedding ( Zero shot inference models don’t require any examples to get an desired outcome). In this method, data is stored as a pair of image and it’s text label is provided in dataset and model have to predict which of the text label is closest to a given image.
This strong image encoder can be used for many type of image classification tasks such as image generation, image search or visual question answering. Flamingo and LLaVa uses CLIP as their image encoder. DALL-E uses CLIP to rerank generated image.
CLIP generally uses 2 encoders, one for image encoding and other is for text encoding. CLIP Uses Transformer model (similar to GPT-2 but smaller) for text encoding and ViT or ResNet models for image encoding and both of these models gives 512 dimension vector embedding which can be visualized in multi dimension space to examine semantic relationships between them.
CLIP is trained on a contrastive learning objective to increase the similarity between image and text description of that image. During training, CLIP is presented with a batch of image-text pairs, where some pairs are matching (i.e., the text describes the image), and others are non-matching (i.e., the text is unrelated to the image). The objective is to learn representations that maximize the cosine similarity between matching pairs and minimize the similarity between non-matching pairs.

The embeddings of both image and text are stored in a embedding space which shows the similarity or a relationship between different images and text pairs. Image and text pairs which are similar will be close to each other in this embedding space.
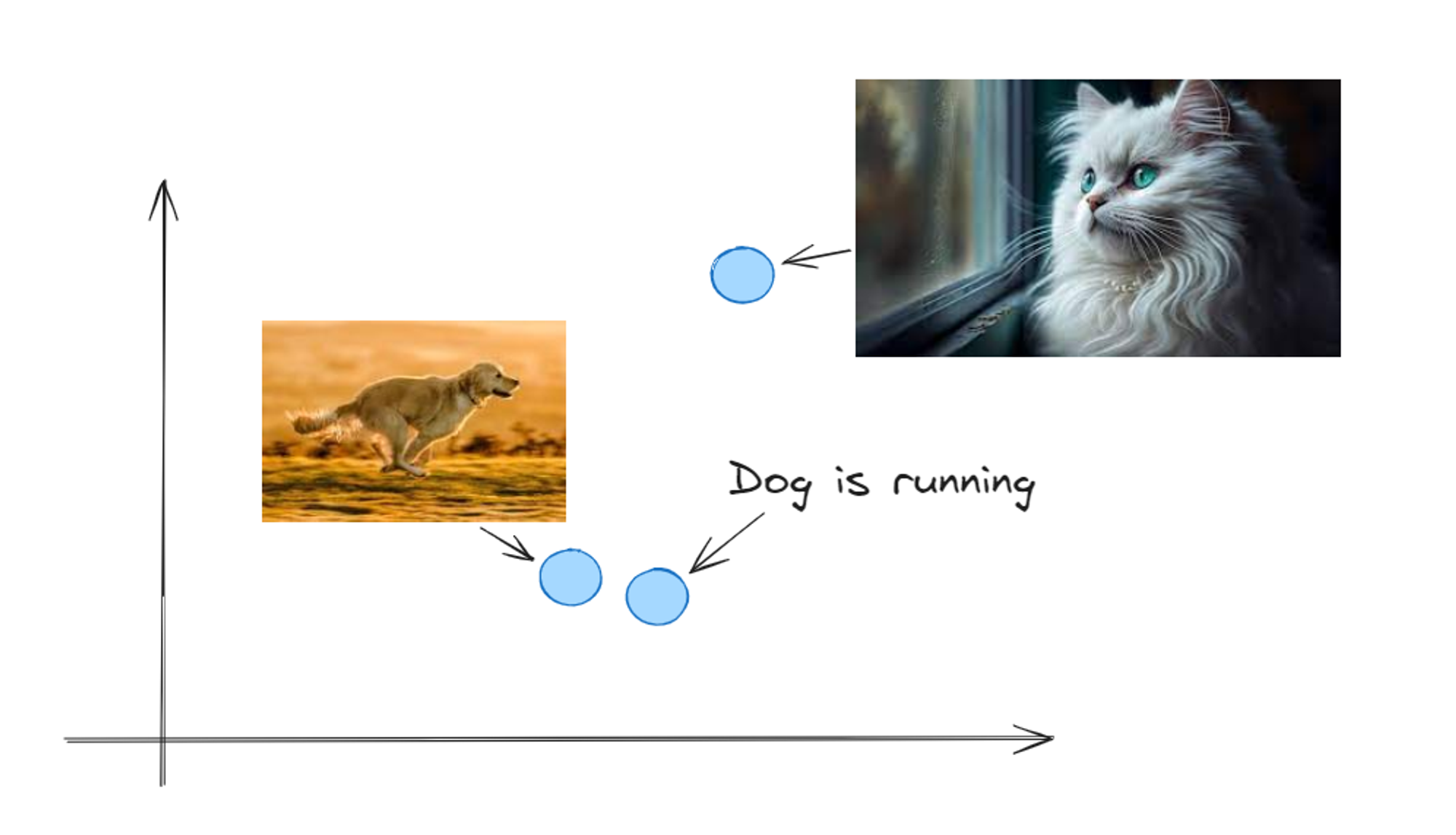
CLIP has demonstrated impressive performance on various multimodal tasks, despite being trained using a simple contrastive objective on large-scale image-text pairs without explicit task supervision. Its success highlights the power of self-supervised learning and the ability of neural networks to learn meaningful representations from raw data.
Flamingo
Flamingo is an another multimodal LLM which was designed for few shot learning. It can also work with images and text but unlike CLIP, flamingo is CLIP + a language model with added techniques to make it possible for the language model to generate text tokens conditioned on both visual and text inputs. In other words, it can generate both text and image responses.
Here is the visual representation of how it can generate both text and images:

Flamingo contains 2 major components in its architecture:
- Vision Encoder: It uses pre trained vision encoder from CLIP. This component takes images or videos as input and converts them into numerical representations (embeddings). However, unlike CLIP which uses both vision encoder and text encoder, Flamingo discards the text encoders and only uses vision encoder for visual information.
- Text Encoder: It uses pre trained chinchilla LLM for text processing. It takes a text as an input and encodes it into similar format as vision encoder’s output.
There are 2 additional components in flamingo which are perceiver resampler and GATED XATTN-DENSE layers but its beyond the scope of this blog for now.
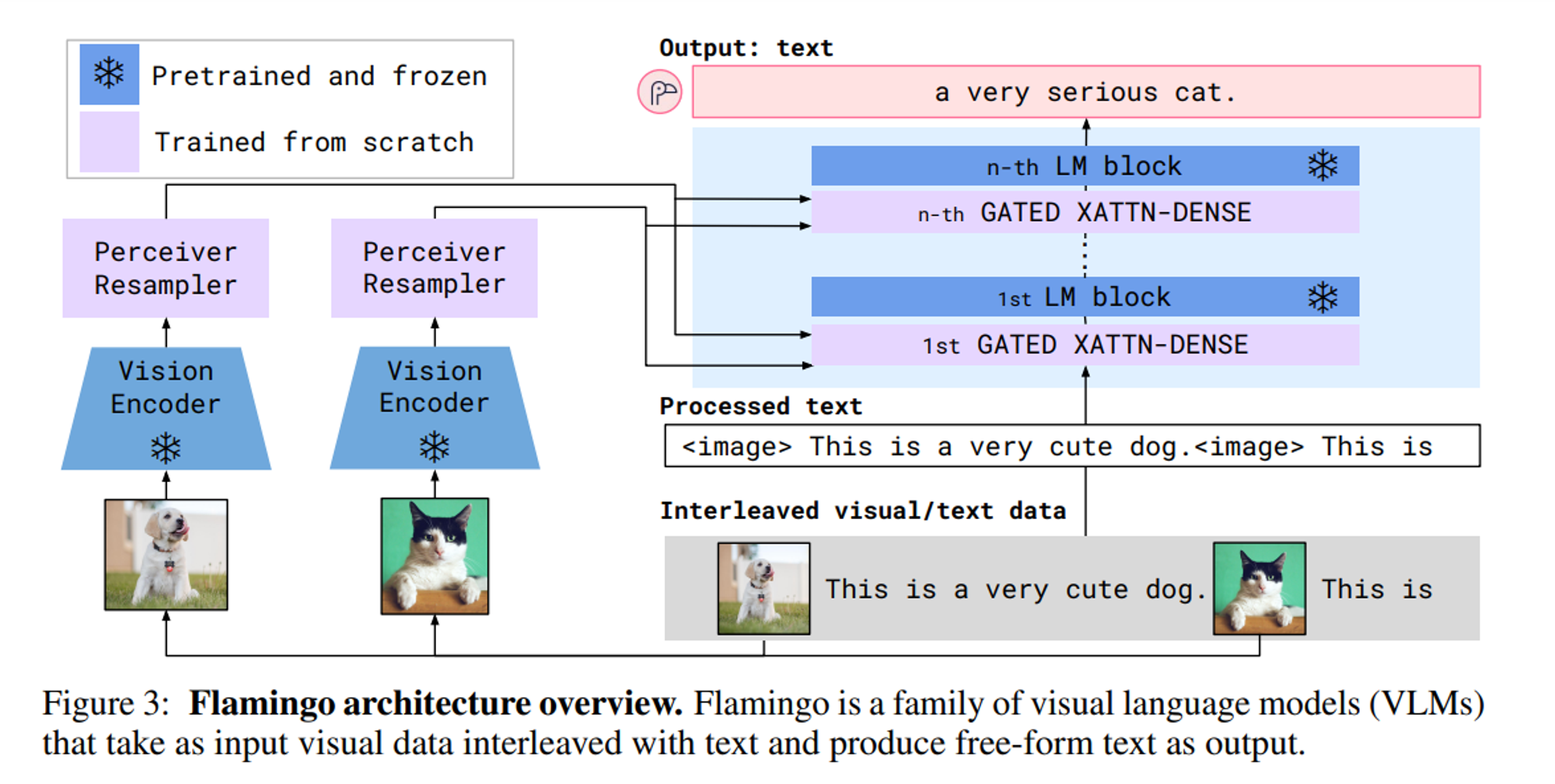
Flamingo is trained on 3 types of datasets:
- Image and text pair datasets
- Video and text pair dataset
- Interleaved image and text dataset
BLIP-2
The BLIP-2 model is also known as “bootstrapping language-image pre-training with frozen image encoders and large language models”. Unlike Flamingo’s focus on pre-trained vision encoders, BLIP-2 uses frozen vision encoder and frozen large language model to improve performance and accuracy by achieving impressive results with fewer parameters.
BLIP-2 was mainly focused on reducing the training cost and it outperforms Flamingo with 80B parameters by 8.7% on zero-shot VQAv2 with 54x fewer trainable parameters.
Here is how the architecture of BLIP-2 looks like:
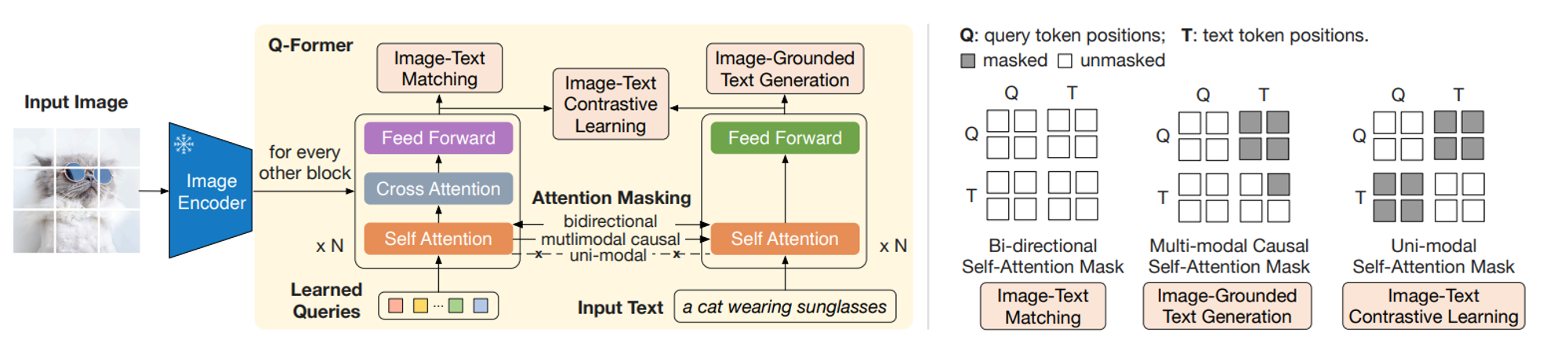
There are 3 main components in BLIP-2 architecture:
- Frozen Image Encoder: It uses a pre-trained image encoder similar to Flamingo but it’s frozen. It means the weights and parameters of this encoder are frozen and will not change during training.
- Frozen LLM: It also uses a frozen large language model so that the weight and parameters of LLMs are fixed during training. This frozen LLM provides powerful text processing capabilities without adding significantly to the trainable parameters.
- Querying Transformer (Q-Former): It is the core component of BLIP-2. It's a lightweight transformer-based model specifically designed to bridge the gap between the frozen image encoder and the frozen LLM. It is used to generate vision and language representations during pre training.
BLIP-2 is trained in 2 stages which are:
- Vision-Language Representation Learning: In this stage, the goal is to align the visual representations generated by the frozen image encoder with the textual representations from the frozen LLM. BLIP-2 achieves this by training the Q-Former on a task called image-text matching. Q-Former finds the similarity score between outputs of image and text encoders.
- Vision-to-Language Generative Learning: Once the Q-Former understands the relationship between visual and textual representations, the second stage focuses on generating text descriptions for images.
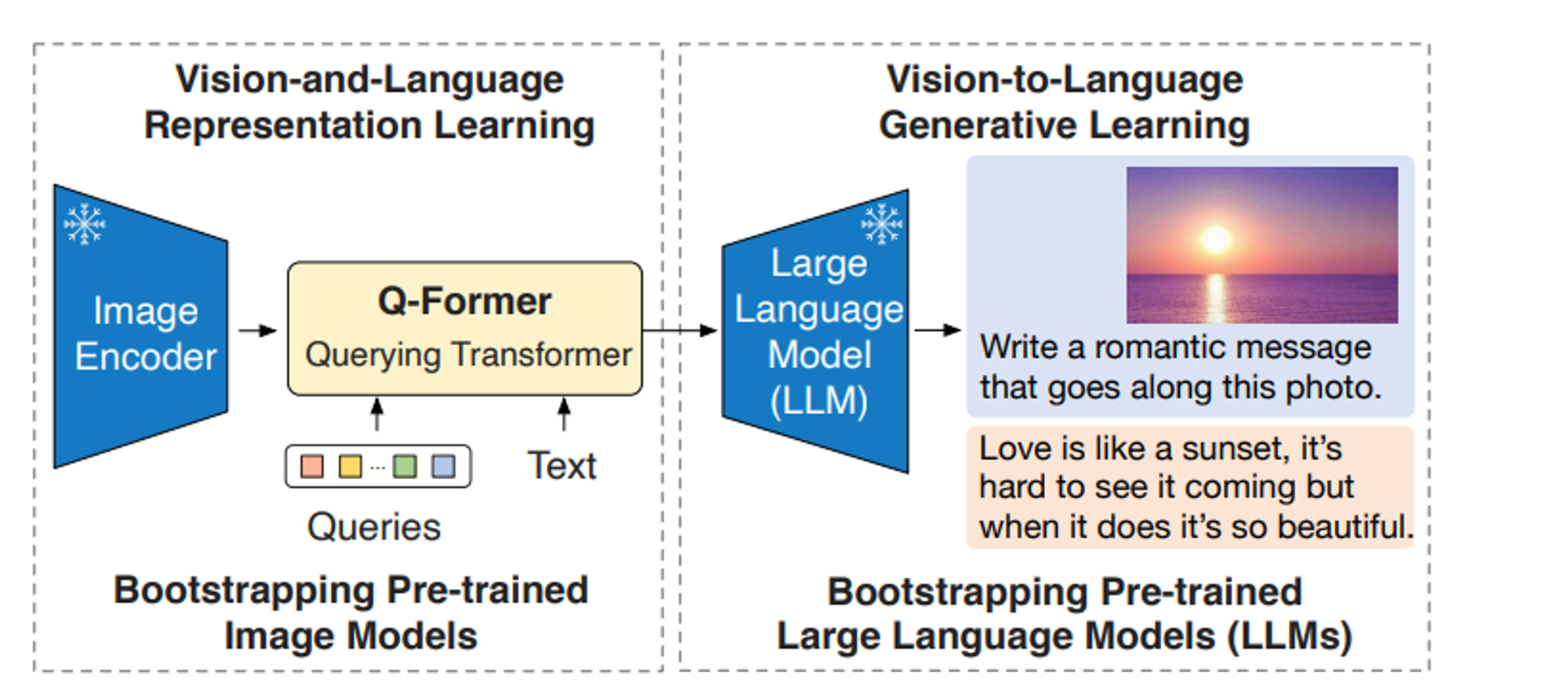
BLIP-2 has demonstrated state-of-the-art performance on various vision-language benchmarks, including image captioning, visual question answering, and multimodal classification tasks.
Applications of Multimodal LLMs
Let’s take a look at some of the real world applications and use cases of multimodal LLMs
- Revolutionizing Search Engines: Currently you can only search using text in most search engines and you can do image search using google image search but imagine you can search for images, audios or videos from single search engine and you can also get results in the form of different modalities. Multimodal LLMs can make revolution in this capability of search engines.
- Boosting E-commerce Experiences: Imagine trying on clothes virtually without leaving your home! Multimodal LLMs could analyze your body measurements and a chosen garment (image or video) to create a realistic simulation of how it would look on you. Also it can provide suggestions on clothes according to your fashion.
- Medical Diagnosis and Treatment: Multimodal LLMs could analyze medical images (X-rays, MRIs) alongside patient medical history and even speech patterns during consultations to assist doctors in diagnosis. They could also generate reports summarizing findings and suggest potential treatment plans based on the combined information.
- Empowering Education: Learning can be more engaging and interactive with multimodal LLMs after support of multiple modalities. It will also increase the ability of customer service chatbots of working with human support tickets by analyzing the images or videos of customer issues to provide more detailed solution or feedback on tickets.
Popular Multimodal LLMs
Let’s take a look at some of the popular multimodal LLMs which uses similar or different techniques/architectures we discussed above.
- GPT-4: OpenAI’s GPT-4 is closed source multimodal LLM and that’s why the underlying architecture is not disclosed but as it is multimodal, it can work with different modalities. Currently GPT-4 can only work with images and text modality but when GPT-5 comes out, we might see support for more modalities.
- Gemini: In 2023, Google announced their own multimodal LLM called gemini which can work with different modalities like images, text, audio and video. Gemini can also do multi modality based question answering, means you can ask questions in the form of more than one modality at the same time. Similar to GPT-4, gemini is also limited to generate image and text responses but both can take multiple modalities as an input.
- LLaVA: LLaVA, or Large Language and Vision Assistant, is a cutting-edge open source multimodal large language model (LLM) developed by Microsoft Research. It can also work with multiple modalities at the same time such as image and text. LLaVA is unique because it's trained on both text and image data simultaneously. This integrated approach is believed to contribute to its strong performance in multimodal tasks.
Future Directions and Trends
Popular multimodal LLMs and techniques like CLIP, Flamingo or BLIP-2 have opened the doors for research and improvement for researchers and multimodal LLMs have became the one of the most interesting topic for researchers and there are still many researches are going on in this and we might see support for more modalities in near future.
After introduction of GPT-5 or future versions of other multimodal LLMs, we might see audio, video generation features along with text and images at the same time by same model. These advancements aim to mimic human-like interactions and push towards artificial general intelligence.
Here are the future trends and research directions according to me:
- Increased Modality Support: While current multimodal LLMs primarily focus on integrating text, images, and sometimes audio, future research is likely to explore incorporating a wider range of modalities. This could include video, 3D data, sensor data, and even virtual or augmented reality inputs. Handling diverse modalities will enable more natural and comprehensive human-machine interactions.
- Self-Supervised Multimodal Learning: Self-supervised learning has been a game-changer for unimodal models, allowing them to learn rich representations from vast amounts of unlabeled data. Future research is likely to explore self-supervised learning techniques specifically tailored for multimodal data, potentially leading to more powerful multimodal representations without relying on extensive annotated datasets.
- Enhanced Reasoning and Grounding: Current MLMs excel at processing information, but the next step is true multimodal reasoning. Imagine an LLM that analyzes a medical image, reads a patient's medical history, and generates a diagnosis with explanations – that's the power of future multimodal reasoning.
- Focus on Explainability and Trust: As MLMs become more complex, ensuring explainability and trust will be paramount. Users will need to understand how these models arrive at their outputs, especially in critical domains like healthcare and finance.
- Challenges and Considerations: While the potential of multimodal LLMs is vast, challenges such as the need for extensive and diverse datasets for training, ethical concerns regarding sensitive data handling, and high computational requirements remain significant considerations in the development and deployment of these models.
Conclusion
As we saw in the blog, multimodal LLMs are next revolution in field of natural language processing(NLP). It have increased the capabilities of simple large language model with multi modality support. The future of AI is likely multimodal, and these intelligent systems are going to play a transformative role in shaping the field of artificial intelligence.
These are just some of the exciting future directions for multimodal LLMs. As research progresses, we can expect even more groundbreaking capabilities that will reshape how we interact with information and the world around us so i will suggest you to keep an eye on latest researches and findings about multimodal LLMs.
Elevate Your Business with Generative AI
The field of artificial intelligence is constantly changing and many businesses are automating their workflows and making their life easier by integrating AI solutions in their products.
Do you have an idea waiting to be realized? Book a call to explore the possibilities of generative AI for your business.
Thanks for reading 😄.