.png)
Since the introduction of ChatGPT, a flurry of new developments has been emerging at an unprecedented rate. New LLMs appear daily, claiming superiority over their predecessors. Have you wondered, "How do LLMs work?"? What feeds their astounding abilities?"
If you've ever wondered about these things, you're in for a fascinating ride. Here, you will find an in-depth guide explaining all you need to know about Language Models, from how they work internally to where they get their extraordinary abilities.
We cover the foundations of LLMs, exploring their respective training procedures, architectural details, and tokenization's smart artistry.
What are Large Language Models?
Natural language processing and prediction are the focus of large language models (LLMs), a subset of deep learning models. These models are intended to capture intricate connections between words and sentences; they are trained on massive volumes of text data like novels, news articles, and social media posts.
When training an LLM, the weights of a previously trained model are often fine-tuned to make it more suitable for the target task. This is termed as the "transfer learning" method. This allows the model to reflect the complexity of the problem more accurately. The "recurrent neural network" (RNN) is a popular kind of LM; it is an artificial neural network that can sequentially process data.
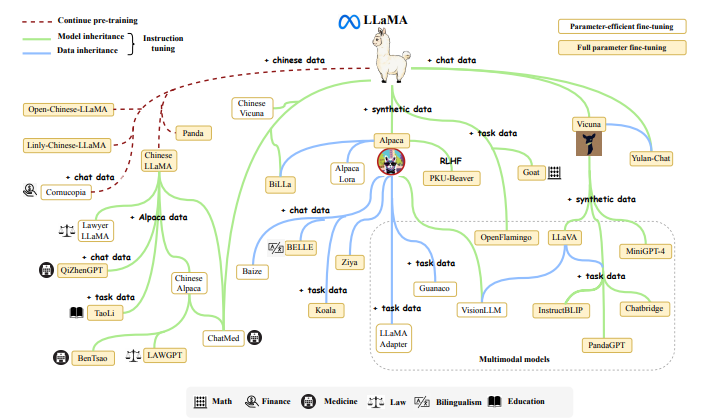
Sources of knowledge of LLMS
The complex nature of developing and reproducing Large Language Models (LLMs) presents challenges in technical intricacies and demanding computational resources.
Publicly Available Model Checkpoints or APIs
Given the substantial cost associated with model pre-training, access to well-trained model checkpoints is vital for research and development within the LLM domain. These model checkpoints vary in parameter scale. This categorization helps users identify suitable resources based on their resource limitations. Additionally, public APIs can be used for inference tasks, eliminating the need to run the model locally. Below are some examples of LLM models and their parameter scales:
- Models with Tens of Billions of Parameters: This category includes models like Flan-T5, CodeGen, UL2, and more. For instance, Flan-T5 (11B version) is noteworthy for research in instruction tuning, while CodeGen (11B version) is designed for generating code and is particularly suited for exploring code generation capabilities.
- Models with Hundreds of Billions of Parameters: Examples in this category include GPT-3 (175B) and PaLM (540B), each with its distinct training datasets and applications.
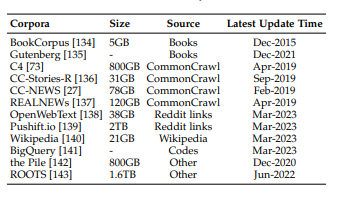
Commonly Used Corpora
In contrast to earlier models, LLMs require substantial training data due to their greater number of parameters. Various accessible training datasets have been released for research purposes. These corpora cover diverse content types, catering to the needs of LLM training. We categorize these corpora into several groups:
- Books: Datasets like BookCorpus and Project Gutenberg offer a collection of books spanning various genres and topics, contributing to training small-scale models.
- CommonCrawl: CommonCrawl provides vast web-crawled data and serves as training material for many LLMs. Datasets like C4, CC-Stories, CC-News, and RealNews are extracted from CommonCrawl, catering to different research needs.
- Reddit Links: OpenWebText and PushShift.io offer datasets extracted from Reddit, serving as valuable resources for model training.
- Wikipedia: With its comprehensive articles on diverse subjects, Wikipedia is widely used in training LLMs. It's available in multiple languages, supporting multilingual training scenarios.
- Code: Code datasets are sourced from open-source repositories like GitHub and platforms like StackOverflow. The BigQuery dataset is a significant source of open-source code snippets.
How do the Large language models work?
Pre-training
Pre-training is a crucial step in developing Large Language Models (LLMs), where they learn essential language skills by being trained on large-scale datasets. This process relies on high-quality data and well-designed techniques. Let's break down the key aspects:
Data Collection
LLMs need a lot of good data to learn effectively. This data comes from various sources and goes through specific processing. Here's what's involved:
- General Data: Most LLMs use a mix of general text data from sources like webpages, books, and conversations. These sources are diverse and offer a wide range of language examples.
- Specialized Data: Some LLMs also use specialized data to improve their performance in specific areas. This includes:
- Multilingual Text: Adding text in multiple languages helps LLMs understand and generate text in different languages. Models like BLOOM and PaLM include multilingual data in their training to perform tasks like translation and summarization in various languages.
- Scientific Text: LLMs can also be trained on scientific publications to understand better and generate scientific content. The growth of scientific research leads to a large volume of scientific papers that can be used for training.
The quality and type of training data greatly impact LLMs' capabilities. The data should be diverse, reliable, and relevant to the models' tasks. For example, using conversations helps LLMs handle dialogue-based tasks while using scientific text improves their scientific understanding.

Model Training and Finetuning
Model training in LLMs involves finetuning the model on a targeted dataset to improve its performance on that task. This task could include any natural language processing operation, such as text production, completion, translation, sentiment analysis, or sentiment analysis.
Batch Training
For language model pre-training, the conventional approach involves using a large batch size, such as 2,048 examples or 4 million tokens. This is done to enhance training stability and throughput. However, GPT-3 and PaLM models have introduced a novel technique of dynamically increasing the batch size during training. For instance, GPT-3's batch size gradually escalates from 32,000 to 3.2 million tokens. Empirical evidence indicates that this dynamic batch size scheduling effectively stabilizes the Large Language Models training process.
Stabilizing the Training
During the pre-training of LLMs, training instability is a common challenge that can lead to model collapse. Practices like weight decay and gradient clipping have been widely adopted to counter this issue. Commonly, gradient clipping thresholds of 1.0 and weight decay rates of 0.1 have been used in previous studies. However, as LLMs scale in size, training loss spikes are more likely to occur, contributing to instability. To mitigate this problem, techniques like PaLM and OPT employ a straightforward strategy - they restart the training process from an earlier checkpoint before the spike occurrence and avoid problematic data. Additionally, GLM identifies abnormal gradients in the embedding layer as a source of spikes and proposes to shrink these gradients to alleviate the issue.
Scalable Training Techniques
With the growth in model and data sizes, efficiently training LLMs within limited computational resources has become challenging. Two primary technical challenges stand out - enhancing training throughput and loading larger models into GPU memory efficiently. Existing literature provides approaches to tackle these challenges, such as 3D parallelism, ZeRO, and mixed precision training. Strategies like 3D parallelism, ZeRO, and mixed precision training have gained traction to address these challenges effectively. 3D parallelism, exemplified by works like this, helps distribute computation across multiple dimensions. ZeRO, as presented in, optimizes memory utilization by partitioning model parameters. Mixed precision training, explored in, leverages lower precision arithmetic to expedite computations without compromising accuracy.
Promptbased learning
Prompt-based learning is used in training Large Language Models (LLMs) that provide explicit prompts or instructions to guide the model's behavior for specific tasks. This approach allows LLMs to perform various tasks without extensive fine-tuning by simply adjusting the prompts. Here's how prompt-based learning works:
- Model Input and Output: If required by the task, the prompt and any additional input are fed as input to the LLM. The model generates an output, typically a response or completion based on the prompt.
- Task Adaptation: The key advantage of prompt-based learning is that the model can adapt to different tasks by adjusting the prompts. For instance, if you want the model to summarize a text, you provide a prompt like "Please summarize the following paragraph." The prompt could be "Translate the following English sentence to French:" if you want a translation. The model's response will be tailored according to the given prompt.
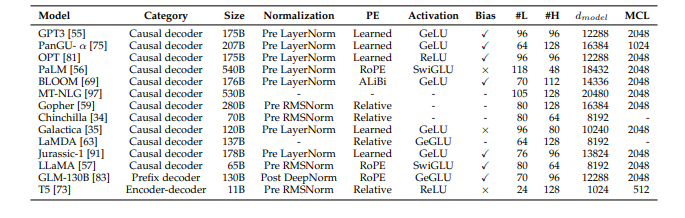
Transformer architecture
The Transformer architecture has become the standard foundation for developing Large Language Models (LLMs) because of its parallelizability and capacity. This architecture has enabled the scaling of language models to billions or even trillions of parameters.
Three main types of architectures are commonly used in existing LLMs:
- Encoder-Decoder Architecture: The original Transformer architecture uses an encoder-decoder setup. It has two parts: an encoder that encodes the input sequence. The decoder generates the output sequence. This architecture is used in models like T5 and BART, which have proven effective for various natural language processing (NLP) tasks.
- Causal Decoder Architecture: The causal decoder architecture involves unidirectional attention, where each token can only attend to the previous tokens and itself. This architecture is used in the GPT-series models like GPT-3. GPT-3 has shown impressive in-context learning capabilities, which allows it to understand and generate text coherently. As seen in GPT-3, scaling plays a significant role in enhancing this architecture's model capacity.

- Prefix Decoder Architecture: The prefix decoder architecture, also known as non-causal decoder, modifies the attention mechanism of causal decoders. It allows bidirectional attention over prefix tokens while maintaining unidirectional attention on generated tokens. This architecture is used in models like GLM-130B and U-PaLM. Models based on prefix decoders have shown promising performance.
These architectures can also be enhanced using the mixture-of-experts (MoE) scaling, where subsets of neural network weights for each input are activated sparsely. This technique has shown performance improvements in various models.

Tokenization methods and techniques
Tokenization is the act of separating individual words or phrases from a larger text. Words, phrases, and sentences are commonly represented using tokens in natural language processing (NLP). Since tokenization allows for the transformation of unstructured text into a structured format. It can be more readily evaluated and processed by machine learning algorithms.
Text Segmentation: The input text is divided into smaller units called tokens. Depending on the specific tokenization strategy used, these tokens can be words, subwords, or even characters. For example, the sentence "ChatGPT is amazing!" might be tokenized into ["Chat," "G," "PT," " is," " amazing," "!"].
Vocabulary Creation: A vocabulary is constructed from the unique tokens found in the training dataset. Each token is assigned a unique token ID. The size of the vocabulary depends on the desired model complexity and the amount of available training data.
Subword Tokenization (Optional): Some LLMs use subword tokenization, where words are broken down into smaller subword units. This is especially useful for handling rare words and morphemes effectively. For instance, the word "unhappiness" might be split into ["un," "happy," "ness"].
Adding Special Tokens: Special tokens are added to the vocabulary to convey specific information to the model. Common special tokens include:
- [PAD]: Used for padding sequences to a fixed length.
- [UNK]: Represents unknown or out-of-vocabulary tokens.
- [CLS]: Denotes the start of a sequence or a classification task.
- [SEP]: Marks the separation between segments in a text.
Assigning Token IDs: Each token in the text is mapped to its corresponding token ID from the vocabulary. These token IDs are used for model computation and learning.
Maximum Sequence Length: LLMs process text in chunks of tokens. There is typically a maximum sequence length that the model can handle. If a text exceeds this length, it may need to be truncated, split into segments, or handled specially.
Padding: Shorter texts may need to be padded with [PAD] tokens to match the required sequence length. The padding ensures that all input sequences have the same length, which is necessary for efficient batch processing.
Special Inputs (Optional): Depending on the LLM architecture and training objectives, additional inputs like position embeddings (to provide positional information of tokens) or attention masks (to indicate which tokens should be attended to) might be prepared.
Input Formatting: The tokenized input is typically converted into a numerical format suitable for feeding into the neural network. This might involve converting token IDs into tensors or other numerical structures.
Training Data Batching: During training, tokenized sequences are grouped into batches to improve computational efficiency. Model updates are computed based on these batches.
But can it help?
Built on a solid data foundation, LLMs can pre-train for linguistic nuances and fine-tune for task perfection. Their tokenization system is brilliant because it turns chaos into order. They can scale and succeed thanks to the revolutionary Transformer designs. As sentinels, LLMs translate text into understanding and replicate human expression in an extraordinary ballet of code and cognition. Language is our bridge.
Curious about what LLM can do for your business? Hear it directly from our CEO, Rohan. Book a free call today!