Introduction
We all know about recommendation systems or search engines where we can get similar texts to user input but have you ever wondered how they work? it works on the basis of vector embeddings which are fundamental concepts for finding semantic relationship between data so lets see what are the embeddings and vectors in brief.
What are Vectors?
Vectors are the numerical representation of any data stored in continuous memory storage (such as arrays or vectors) which can help to find semantic similarities between any 2 data. these vectors represent any of the data points mentioned above in a continuous space.
Here the word semantic plays a big role because here we are not comparing 2 words for their grammatical or character similarity ( for example ‘car’ and ‘cat’ ) but here we will be comparing the words by their real meanings ( for example ‘puppy’ and ‘dog’ ) and that is where vectors helps us to find out similar words.
What are Embeddings?
Embeddings are a fundamental concept in natural language processing and machine learning. The terms vectors and embeddings are very similar but embeddings refers to the process or technique to converting data into vectors using specific algorithms or models while vector is the numerical representation of data.
In short, embeddings and vectors can be used interchangeably in the context of vector embeddings, "embeddings" emphasizes the process of representing data in a meaningful and structured way, while "vectors" refers to the numerical representation itself.
Types of embeddings
You can embed any kind of data like words, sentences, documents or even images too and all these different kind of embeddings allows us to properly structure and visualize the data for different use cases ( for example, image search works on image embeddings which we will talk about later in this article)
Here are some of the common embedding types:
Text Embeddings
Text embeddings are most commonly used embedding type in machine learning. Text embeddings are used to find semantic relationships between words. For example, the words “dog” and “puppy” have similar meaning that’s why the vector embeddings of these 2 words will be close to each other in n dimension representation.
Let’s see it in action by creating an embedding using OpenAI embeddings.
- First go to OpenAI’s website and create an account.
- Once you have created an account, go to API Keys section and click on “Create new secret key”
Give a name to your api key and click on create and you will get your api key now let’s come to coding part.
3. We will use javascript in this example to generate a script which will take an input string and return embeddings for that string. So let’s start by installing openai package from npm:

4. Now let’s first store our openAI key in a constant or environment variable because this key is private and should not be shared with anyone.

5. Now let’s take a look at our script
After running the above script, we will see a prompt asking for an input and once we give an input, we will get an embedding which looks like this
Let’s take a look at “embedding” field which contains the actual embedding vector
As we can see, we have got the embeddings for this sentence and similarly we can generate embeddings for multiple sentences to find semantic relationship between them.
Image Embeddings
Image embeddings are used to show images as vector of numbers. These vectors can find similarities between images and also it can be used to find out similar images for an image and also can be used in image recognition. OpenAI CLIP is the example of techniques which can be used to create image embeddings.
Document Embeddings
As the name suggests, document embeddings are used to embed whole documents instead of single word or sentence and it can be very useful for various tasks such as document classification, information retrieval from document or recommendation systems for documents. Doc2Vec is the one of the technique used to convert document into vector embeddings.
How are vector embeddings created?
Let’s take a basic example.
Suppose you have many balls of three different colors and you want to sort them in a way that when a new ball is added, it can easily fit in with similar ones or match the existing ones.
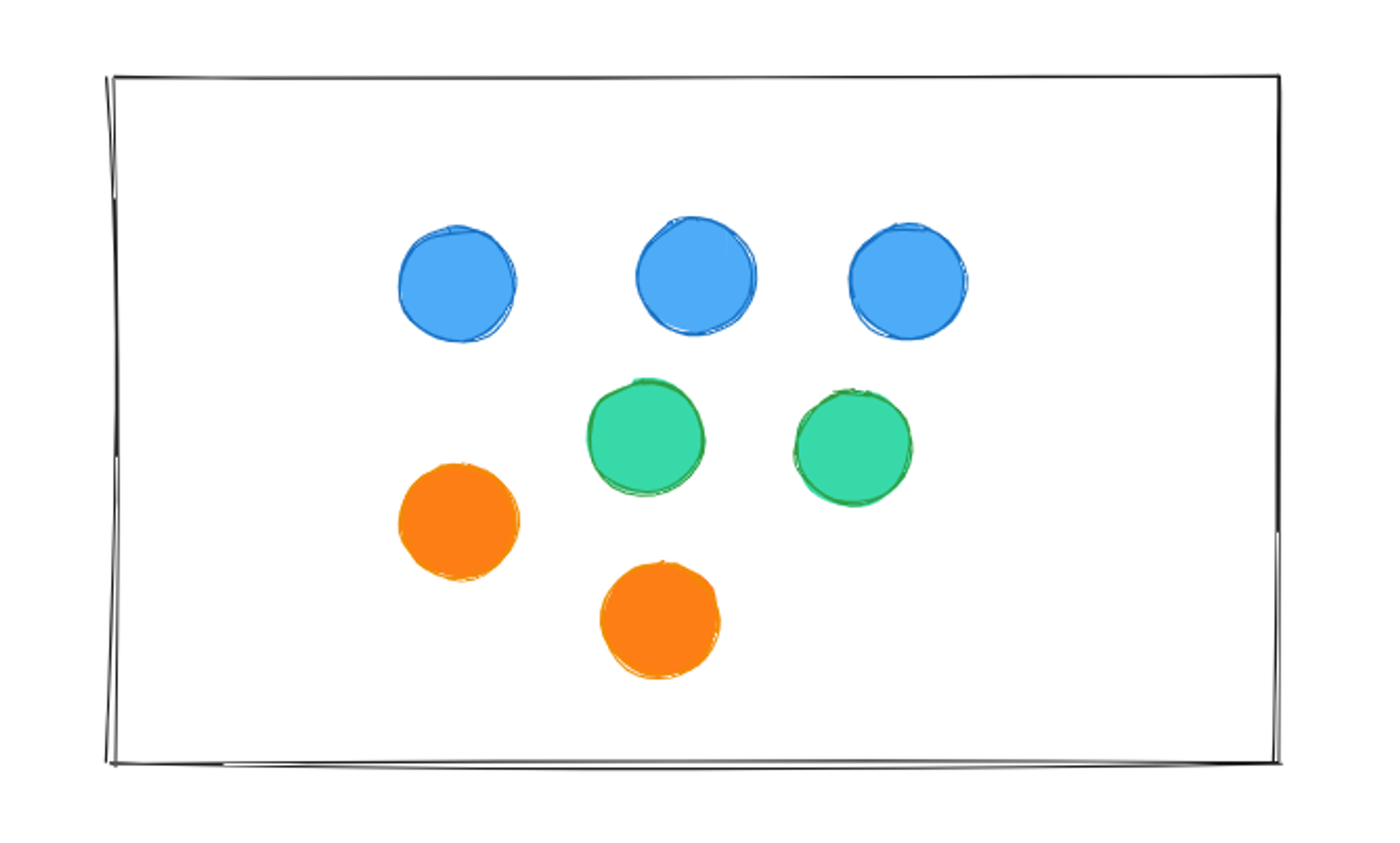
We will categorize all balls based on their color because that’s what which makes them unique in this scenario. After categorizing, the balls will look like this
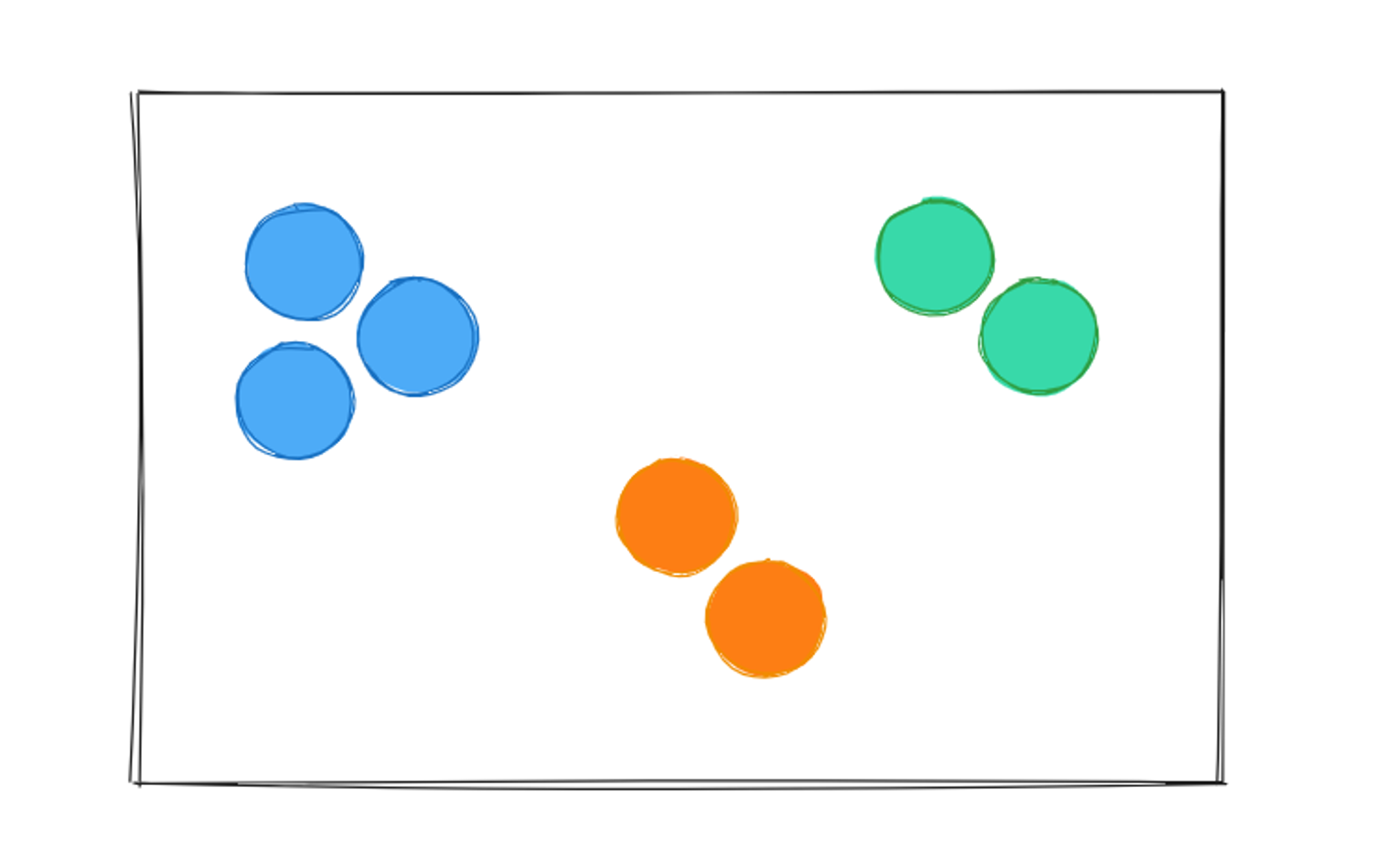
As we can see, all the similar balls are close to each other and all the unique balls are far from each other and now if i want to add a new ball in this table then it will be easy for me to find out the perfect place for this new ball based on its color. This technique of grouping out same color balls is called “clustering”.
Vector embeddings works on the same way and takes this visual representation and applies a mathematical representation to its position.
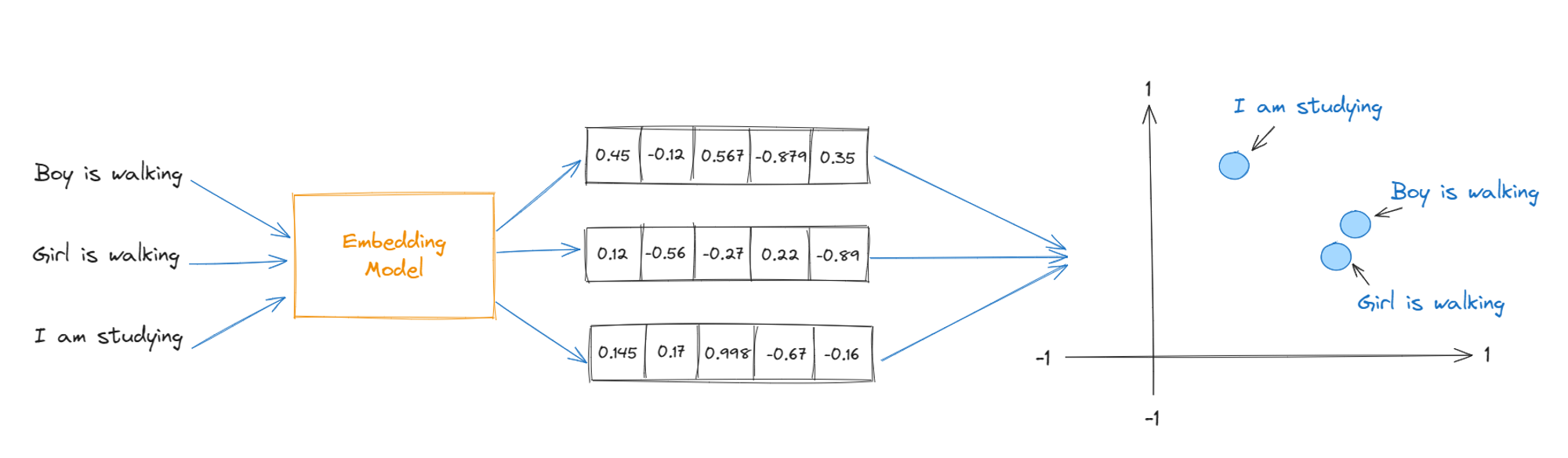
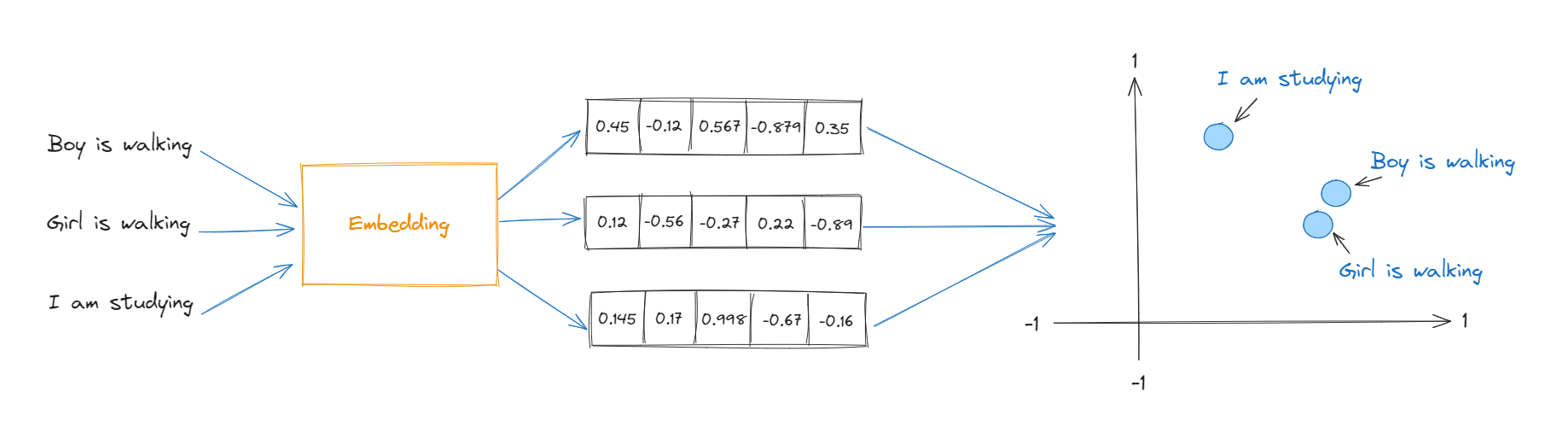
This is how a vector embedding for words will look like:
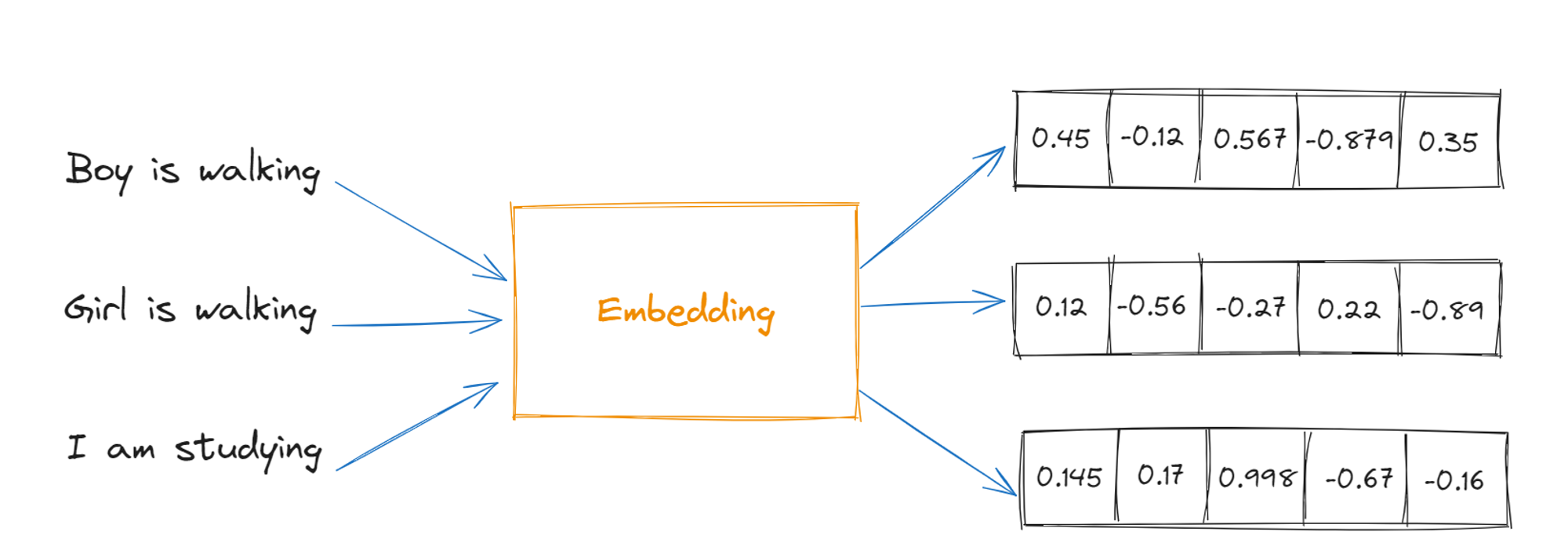
Every vector embedding will be unique and every element in vector will be in range [-1,1] because the cosine values can only be in this range. We can use these vectors to represent them in nth dimension canvas or storage for visualization.
This is how it will look like in 2D Graph
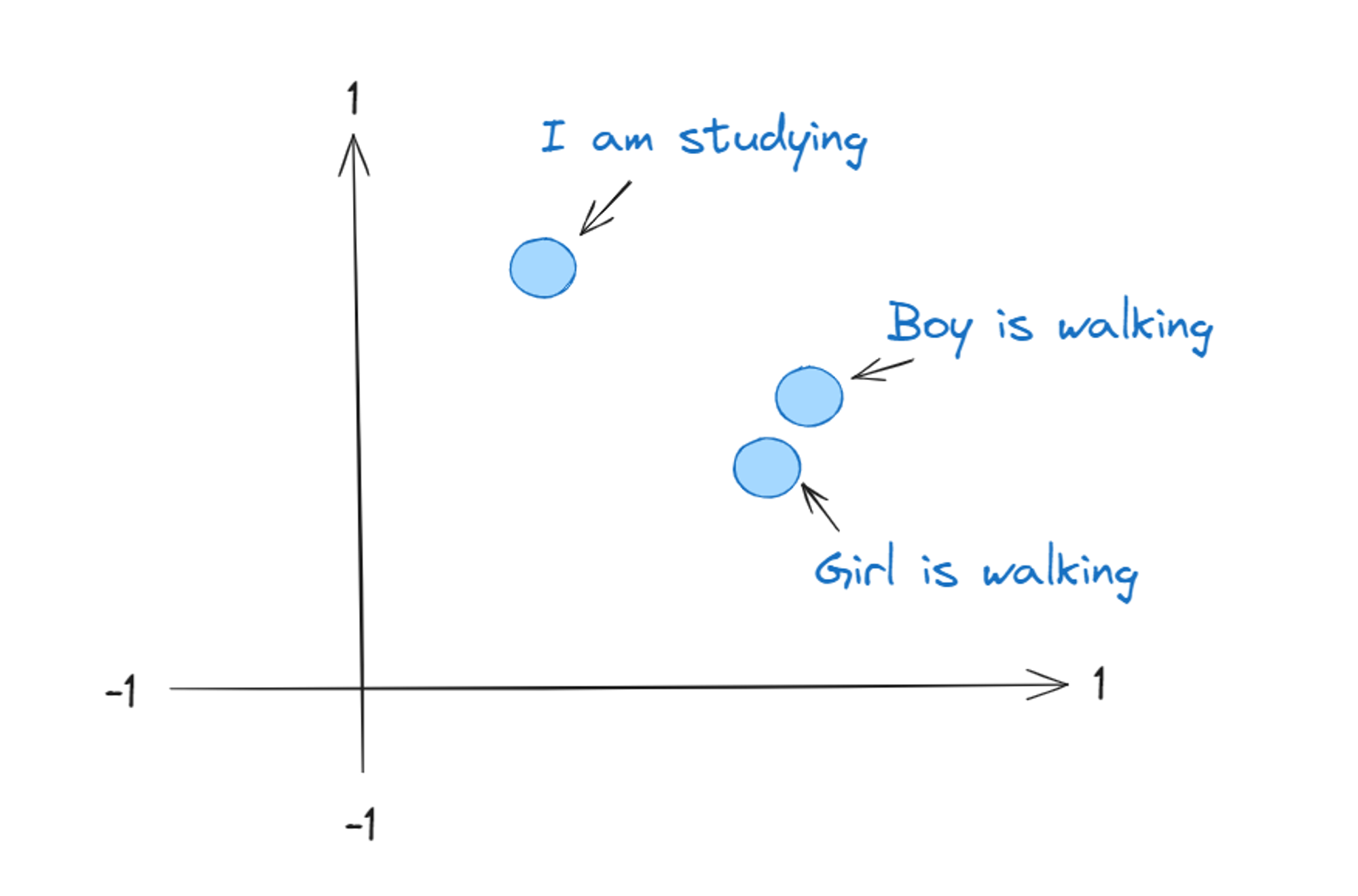
In the graphical representation of vectors, the most similar words will stay closer to each other and 2 different words will stay far from each other so that it can be easy to get the similarity score of each of these sentences to the given number.
Vector embeddings can be made using variety of techniques. You can choose a technique based on your use case and datasets. Some of the techniques used to create vector embeddings are:
- Word2Vec - Word2vec is a technique in natural language processing (NLP) for obtaining vector representations of words.
- OpenAI Embeddings - OpenAI provides one of the most easy technique to create embeddings using their models
- GloVe - GloVe is an unsupervised learning algorithm for obtaining vector representations for words created by standford nlp.
- fastText - FastText is an open-source, free, lightweight library that allows users to learn text representations and text classifiers.
- ELMo - ELMo is an NLP framework developed by AllenNLP. ELMo word vectors are calculated using a two-layer bidirectional language model (biLM). Each layer comprises forward and backward pass.
How to use Vector Embeddings?
So now we know that what are embeddings and how they are created but you might be thinking that where it gets applied and how its useful. As we already know that vector embeddings can be used to find the semantic relationship or similarity between data so we can use it in recommendation system or to search data.
These are the main use cases of vector embeddings
- Semantic searches
- Machine learning and deep learning
- LLMs and generative AI
Let’s take a look at some of the most common use cases of vector embeddings.
Recommendation systems
Vector-based recommendation systems take a different approach by representing items and users as vectors in a multi-dimensional space. In this space, similar items and users are located closer to each other. The concept is similar to mapping user preferences and item attributes in a common vector space, making it easier to measure similarity and make recommendations.
Image embeddings
Images can also be embedded to find similarity between images, find objects in an image or find similar image for an given image and this all can be achieved using vector embedding.
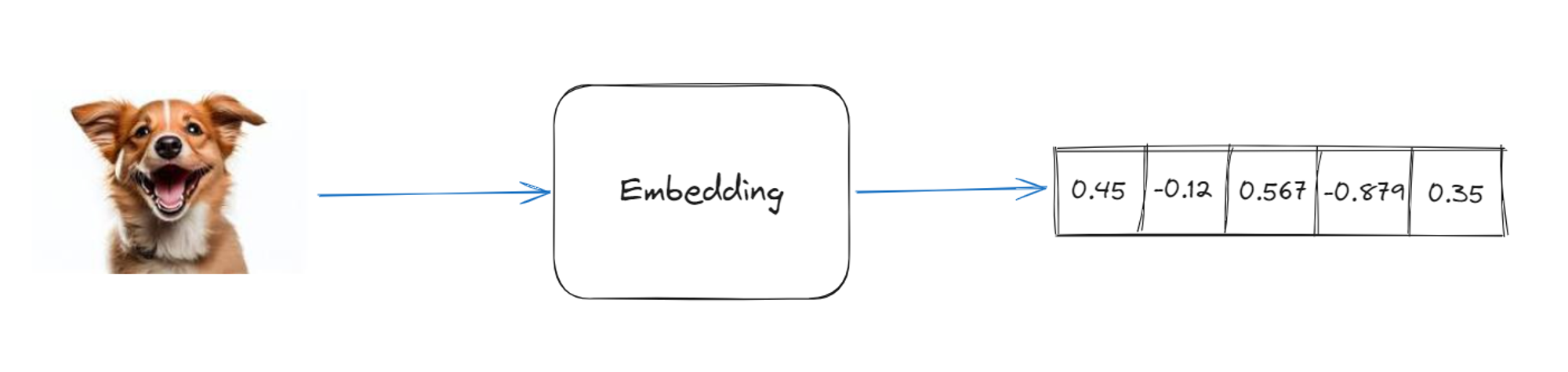
Now let's discuss CLIP, a popular image embedding model created by OpenAI, then walk through a few examples of embeddings to see what you can do with embeddings.
CLIP (Contrastive Language-Image Pretraining)
In 2021, OpenAI Researchers introduced a research paper in which they introduced a zero shot inference technique for image embedding ( Zero shot inference models don’t require any examples to get an desired outcome). In this method, data is stored as a pair of image and it’s text label is provided in dataset and model have to predict which of the text label is closest to a given image.
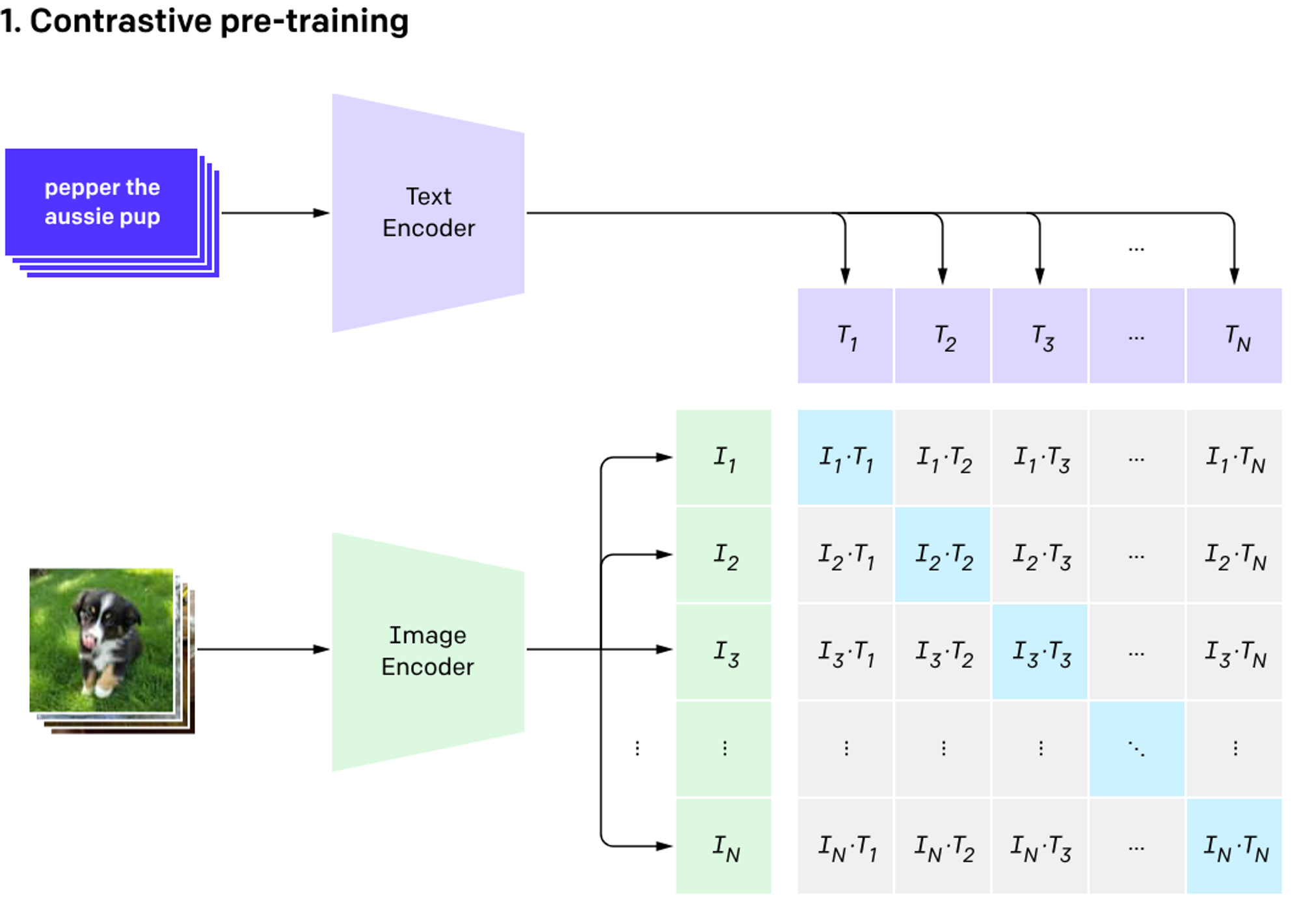
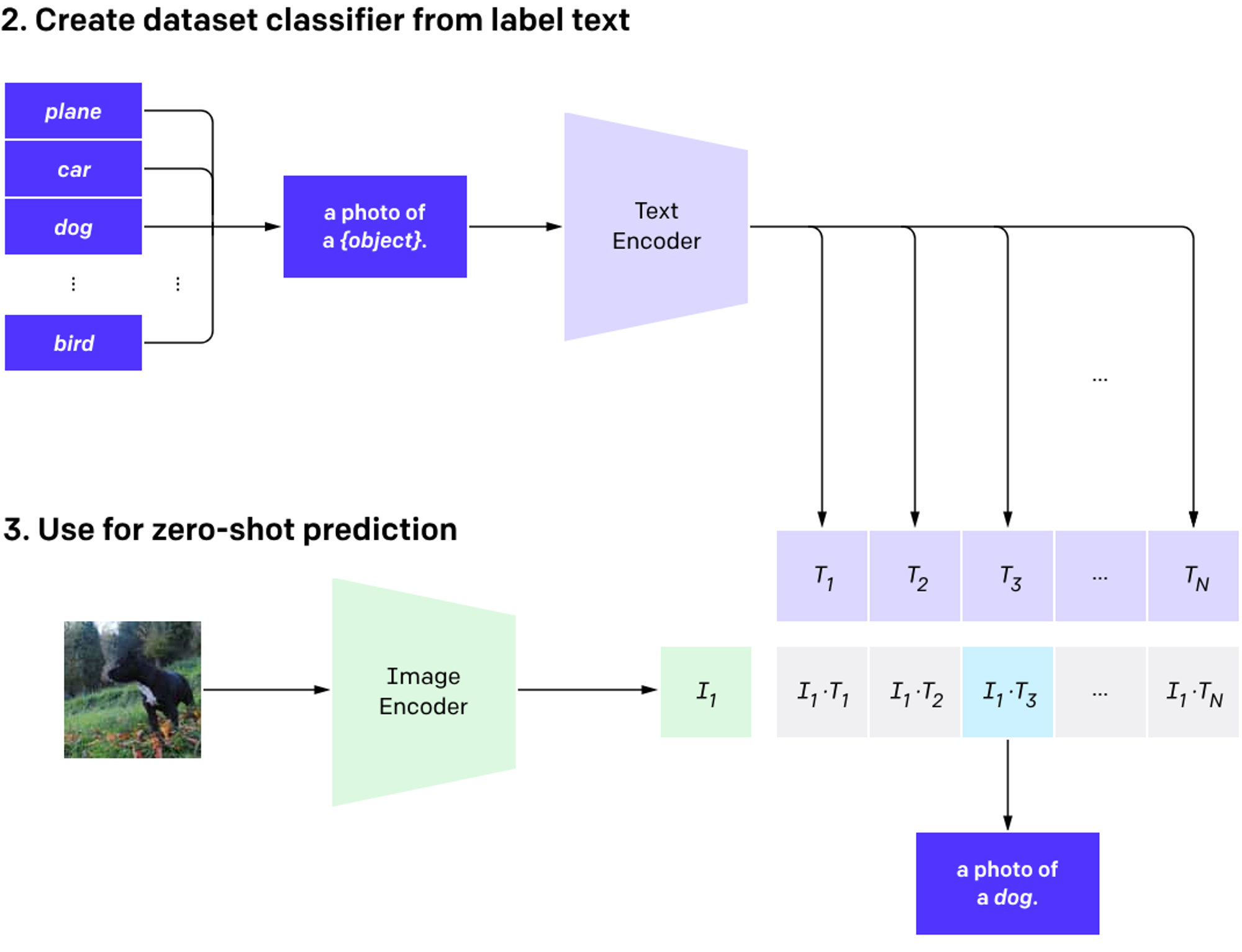
After converting both images and its relevant text in vector embeddings, we can create content based image retrieval system by providing an image or text using CLIP. This works on the same technique of finding a similar text for a given text as we discussed before but in this case we have to find an image which is relevant to text or vice versa.
There are 2 main encoders in CLIP architecture:
- Text encoder
- Image encoder
CLIP Uses Transformer models for text encoding and ViT or ResNet models for image encoding and both of these models gives 512 dimension vector embedding which can be visualized in multi dimension space to examine semantic relationships between them.
This is how images and text will look in multi dimensional space after converting them into vectors.
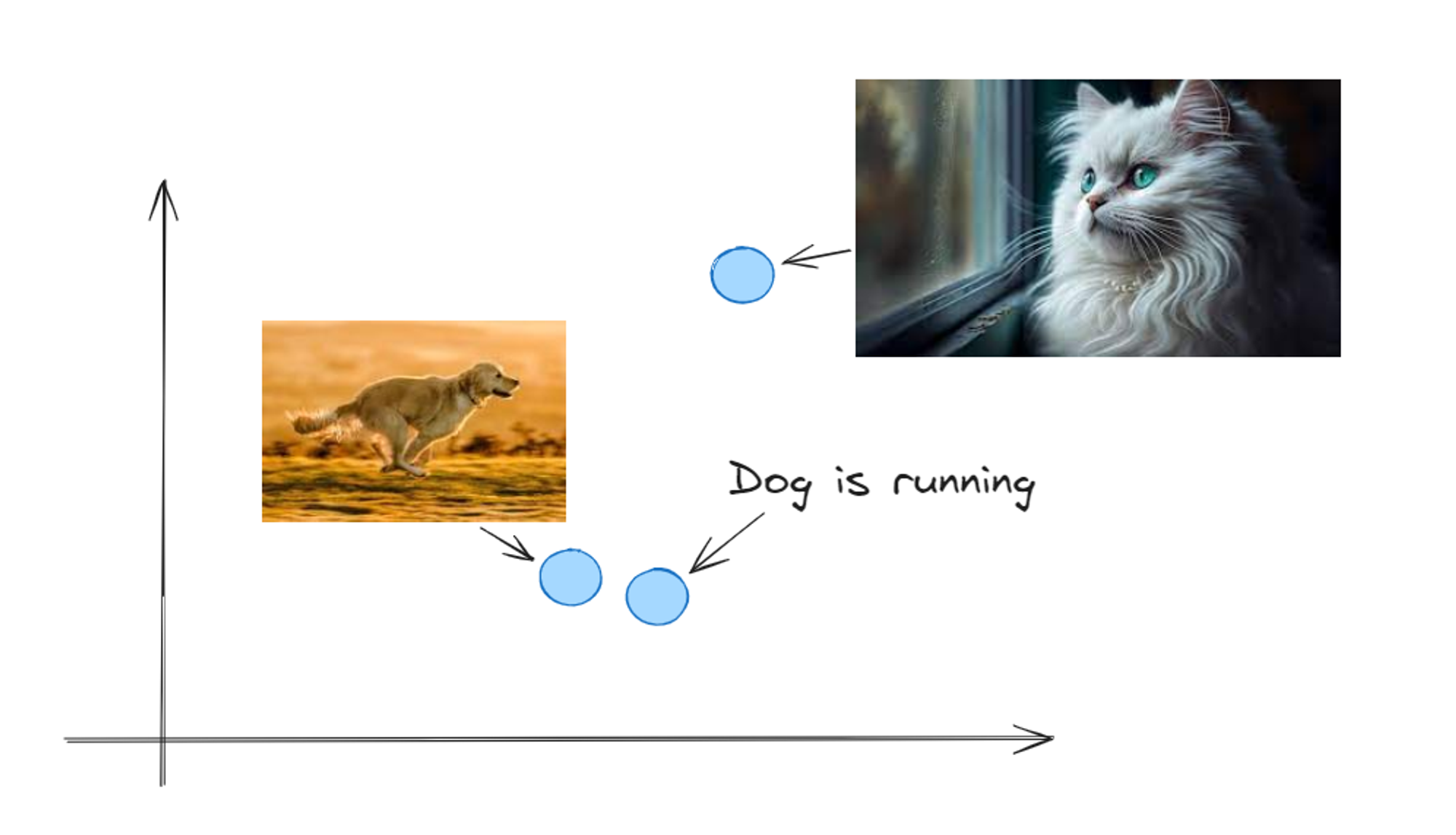
As we can see, the text “Dog is running” is more relevant to the dog image and that’s why those 2 vectors are close to each other in multi dimensional space. Google’s image search works on similar technique to this where we can search similar images for the given image.
You can also apply this technique to embed videos but the only catch is that you will have to embed a frame of video to visualize data in that video.
How to store vector embeddings?
Vectors can be stored in a special type of databases known as “vector databases”. A vector database is a specific kind of database that saves information in the form of multi-dimensional vectors representing certain characteristics or qualities. There are many database providers which provides this service such as
You can use programming languages like python or javascript to interact with these databases just like any other type of database.
Why vector embeddings are important for your model?
Vector embeddings are pivotal for enhancing the performance and capabilities of your model in AI, ML, and LLM applications. Here's why they are crucial:
- Complex Relationship Representation: Vector embeddings excel in representing intricate relationships and semantics within data.
- Meaningful Information Capture: By transforming raw data into dense vector representations, embeddings capture meaningful information about entities, words, or phrases in a continuous vector space.
- Improved Understanding: This transformation enables models to better understand the underlying structure and context of the data, leading to more accurate predictions and insights.
- Streamlined Tasks: Vector embeddings facilitate various tasks such as similarity comparison, classification, clustering, and recommendation systems by encoding latent features that encapsulate both semantic and syntactic similarities among different data points.
- Dimensionality Reduction: Embeddings contribute to dimensionality reduction in the input space, making it more computationally efficient to process and analyze vast datasets.
Integrating vector embeddings into your model amplifies its ability to extract meaningful patterns and relationships from data, thereby elevating its performance and applicability across diverse domains within AI and ML.
Conclusion
Vector embeddings have improved machine learning models by providing numerical representation of different data like text, images, documents or videos and making it easy to digest and process. Even if we don’t use embeddings directly for an application, many popular ML models and methods internally rely on them.
As the field of AI and machine learning continues to evolve, embeddings will no doubt continue to play a pivotal role in shaping the future of machine learning and artificial intelligence.
Looking to build with embeddings?
Are you looking for best AI Solutions for your model or have an idea to build any SaaS using AI then we at ionio have done lot of work on LLMs, Embeddings and delivered multiple AI-Powered SaaS products. If you are interested then kindly book a call with us.