.png)
Imagine a world where machines can understand our words and intentions. Where they're capable to give thoughtful and nuanced responses. This is not a distant dream, but has become an AI reality. This shift is being propelled by the use of Large Language Models (LLMs) such as GPT and Anthropic's Claude. Language models are undergoing continuous improvement as time is passing. One such example is the application of Reinforcement Learning from Human Feedback. But why enhance something that is already at the forefront? The solution lies in finding AI that can communicate well. The one which must understand human values and intentions.
LLMs like Chat GPT use their generative abilities to create human-like text. They balance between making deterministic and creative outputs through sampling. LLMs were trained on vast datasets to learn grammar, syntax, and worldly knowledge. But, they struggle to align responses with human intentions. To fix this, they get fine-tuning instruction. It uses high-quality instruction-response pairs. This changes them from text completers to helpful assistants. RLHF refines models more. It uses human feedback. This aligns models with human values and preferences. It also boosts their abilities by nudging them closer to human-level understanding and responding.
Instruction Fine-tuning vs RLHF:
The goal of instruction fine-tuning is to align LLM intents with human intentions. This is particularly important when responding to specific instructions or requests. But, RLHF aims to align the LLM with the values and preferences of individuals. It enhances the accuracy of model predictions and enhances the overall performance.
- Data Source: The data used for training is a refined form of instruction. It involves high-quality instruction-response pairings. We select and usually obtain the pairs from human interactions. Offering precise and contextually appropriate responses. Whereas, the RLHF training data comprises user input from various interactions. Receiving input from users allows the model to strengthen their preferences. It can then adjust its actions accordingly.
- Model-training: The training process uses carefully selected instruction-response pairs to refine the pre-trained LLM. It does this following self-supervised learning. The model becomes better at responding in a manner that aligns with the user's instructions. In reinforcement learning, receiving positive feedback from users reinforces positive behavior.
- Response: The LLM improves by refining instruction. This helps it to assist by following and giving correct responses. While RLHF focuses on making the model more versatile. Making it able generate grammatically correct as well as natural-sounding speech.
Reinforcement Learning with Human Feedback (RLHF):
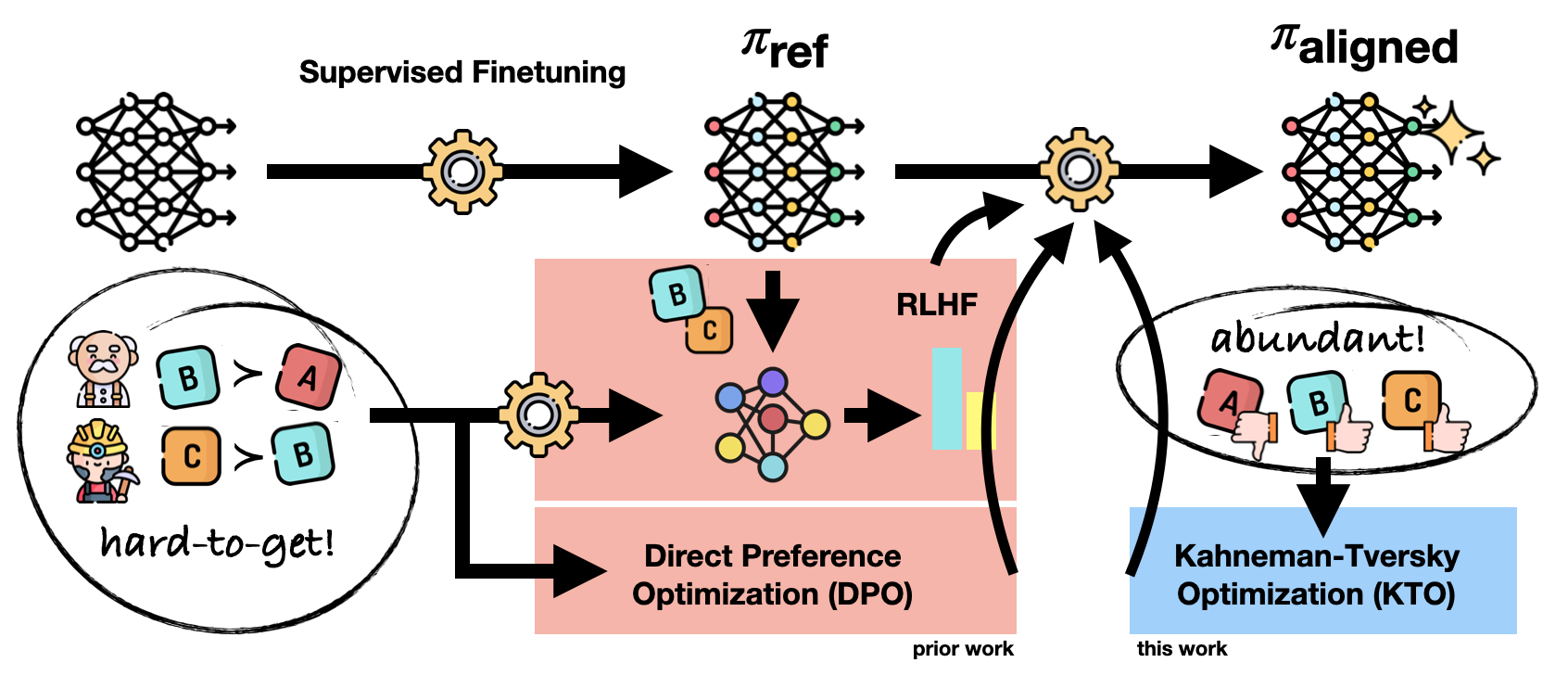
RLHF, as the name suggests, stands for Reinforcement Learning through Human Feedback. It's used to finetune the LLM with human feedback data. This results in a model that is better aligned with human preferences and minimizes the LLM's potential to harm. In RLHF, LLM is refined using reinforcement learning from human input to follow several written commands. Human preferences are used as a reward signal to refine models. We first gather 40 contractors to categorize our data based on their screening test scores. We collect labeler-written prompts. We also collect human-written demonstrations of the desired output behavior on model-submitted prompts. The supervised learning baselines are trained on this dataset. After that, we collect human-labeled comparisons of our model outputs on more API prompts. We train a reward model (RM) on this dataset to predict our labelers' preferred model output. Finally, we use this RM as a reward function and modify our supervised learning baseline using the PPO algorithm to maximize it.

Large language models (LLMs) fine-tuned through reinforcement learning from human feedback (RLHF), as seen in widely used AI models like Open AI’s Chat GPT or Anthropic’s Claude, present challenges in understanding the nuances of each RLHF stage. Analyzing supervised fine-tuning (SFT), reward modeling, and RLHF, and their impact on out-of-distribution (OOD) generalization. OOD generalization proves vital for diverse real-world scenarios, while output diversity, essential across use cases, diminishes significantly in RLHF compared to SFT. This reveals a tradeoff between generalization and diversity in current LLM fine-tuning methods. Therefore, we use Reward models to train LLMs for creating more natural sounding responses.
Reward Models
Creating a reward model is essential for RLHF. It entails fine-tuning a system to generate rewards that reflect human preferences for a specific text sequence. This is vital for seamlessly integrating RL algorithms. We adjust language models or models created from scratch using preference data. For example, Anthropic utilizes preference model pretraining (PMP) to enhance efficiency. Outputs are ranked by human annotators, and a regularized dataset is created using methods like Elo system comparisons. RLHF systems utilize reward models of different scales compared to text generation capacity, which enhances comprehension and optimization.
Reward models play a significant role in RLHF as they address the challenge of aligning language models with human preferences. Ranking methods offer a solution to the challenge of obtaining calibrated and noise-free "scalar scores" or reduced "toxicity score” from human annotators. Data collection involves sampling prompts from predefined datasets and generating text outputs for ranking. Successful RLHF systems, such as Open AI's 175B LM and 6B reward model, highlight the significance of aligning preference models with text generation in terms of capacity.
.png)
In RLHF, by incorporating reinforcement learning (RL), the language model is able to adapt and improve its language generation abilities based on human preferences. It creates a robust system that learns and adapts to diverse preferences. The reward model evaluates the pair based on the human feedback it was trained on, and returns a reward value. Higher rerd value
Data collection and training in RLHF and reward hacking:
Collecting human feedback: This process involves defining the criteria for human assessment and obtaining human feedback through the labeler workforce for the generated prompt-response sets. For a given prompt X, the reward model learns to favor the human-preferred completion y_j, while minimizing the log sigmoid of the reward difference (r_j - r_k).
Preparing labeled data for training (or the reward model): It involves converting rankings into pairwise training data for the reward model. The completion pairs {y_j, y_k} are prepared such that y_j is always the preferred option. The model is then trained to predict the preferred completion/response from {yj, yk} for the prompt x. Finally, the reward model is used as a classifier to provide the reward value for each prompt-completion pair.
Once the model has been trained on the human rank prompt-completion pairs, Reward model is used as a binary classifier to provide a set of logits across the positive and negative classes. Logits are the unnormalized model outputs before applying any activation function. The two classes would be notate, the positive class that ultimately needs to be optimized for and the negative class that is to be avoided. The largest value of the positive class is what is used as the reward value in RLHF. And then SoftMax function is applied to get the probabilities.
Fine-tuning with RLHF
The fine-tuning process in RLH involves an iterative loop with the following steps:
Fine-tuned LLM -->Reward model -->RL algorithm -->RL-updated LLM --> (back to Reward model)
The instruction fine-tuned LLM initiates the process by providing instructions to the concerned language model. The reward model evaluates the model's output, assigning scores based on desired parameters. Utilizing the reinforcement learning (RL) algorithm, the model is updated to maximize rewards, thus, detoxifying its responses. The RL-updated LLM generates new output, reiterating the cycle by feeding the outputs generated as input to the reward model. These series of steps together forms a single iteration of the RLHF process. These iterations continue for a given number of epochs, similar to other types of fine tuning. Continuous iterations refine the model, with the reward model consistently assessing and providing feedback.
.png)
RL Optimization Algorithms
RL algorithm is the algorithm that takes the output of the reward model and uses it to update the LLM model weights so that the reward score increases over time. Although we have several algorithms such as:
- Minorize-Maximization Algorithm, which works iteratively by maximizing a lower bound function M.
- Line search, like the gradient descent and the trust region, Gradient descent is easy, fast and simple in optimizing an objective function.
- Policy gradient, which is mainly an on-policy method. It searches actions from the current state.
- PPO (Proximal Policy Optimization)
- DPO (Direct Preference Optimization)
- KTO (Kahneman-Tversky Optimization)
.png)
PPO vs DPO vs KTO
PPO (Proximal Policy Optimization)
Lets consider an agent learning to generate completions. Trying different words and learning a policy that predicts which action to take in each state (situation). The policy is updated based on experience. But, instead of changing the policy a lot based on recent success or failure, PPO makes small, incremental changes. It compels the agent to avoid big strategy changes based on limited information. This leads to a more stable learning process.
Proximal Policy Optimization (PPO) is designed with a specific objective function that helps in stabilizing and improving the training process in reinforcement learning. The objective function of PPO and the role of KL divergence in it can be described as follows:
.png)
PPO uses the policy gradient approach. The agent learns a policy directly. The policy is usually parameterized by a neural network. The policy maps states to actions based on the current understanding of the environment.
Iterative Policy Improvement: The agent collects a set of trajectories under its current policy. Then, it updates the policy to maximize a specially designed objective function. This process is repeated iteratively, allowing the policy to gradually improve over time.
PPO improves stability and reliability in reinforcement learning through a clipping mechanism. This mechanism prevents any disruptive updates to the policy, resulting in a smoother learning process. The efficiency of this approach comes from reusing data for multiple gradient updates, which leads to better sample efficiency compared to other methods. PPO demonstrates its adaptability by providing strong performance in a wide range of environments, from straightforward control tasks to complex 3D simulations. PPO, due to its straightforward concept stands out from previous algorithms like TRPO, which introduces a "trust region" constraining the extent to which a policy can change in each iteration.
Objective Function in PPO:
Policy Ratio: The Policy Ratio is the core of the PPO objective function. It's the ratio of the chance of taking an action under the current policy to the chance under the old policy. The ratio is multiplied by the advantage estimate. This estimate shows how much better a specific action is than the average action in a state.
Clipped SurrogateThe Clipped Surrogate Objective has a specific range. It's usually [1−ϵ,1+ϵ] (where ϵ is a small value like 0.1 or 0.2). This clipping ensures that the policy changes are not too big. Thus preserving stability during the training.
Value Function Loss: The value function loss aims to maximize estimated state value accuracy. This accuracy is crucial for getting reliable advantage estimates.
Entropy Bonus: Certain versions of PPO incorporate an added incentive to promote exploration. This part of the objective function encourages the policy to take many actions. This helps avoid avoid premature convergence to suboptimal policies.
Reward Hacking:
Reward hacking is common in machine learning. A model cleverly manipulates the reward system to get high scores. But, it doesn't actually address the original problem. It lets it cut the loss without fully grasping the problem's key parts. This problem can result in models that excel during training but struggle to perform in real-life situations. This can appear in different ways in LLMs like GPT-4. Ranging from imitating styles without making real content to being too cautious in responses. Hallucinations are a prime example of reward hacking. The LLM makes their content look pleasing to humans, even if it lacks facts.We utilize the original instruct model as a reference for our RLHF model to ensure it remains close to the original LLM. We measure the difference between the distributions using the KL (Kullback-Leibler) Divergence Shift Penalty. KL divergence measures their dissimilarity. It does so when tested against the Reference (frozen-original LLM) and RL updated LLM. PPO uses KL divergence. It keeps the updated policy close to the original. This helps avoid premature convergence to suboptimal policies.
KL Divergence:
KL-Divergence is a mathematical measure that quantifies the disparity between two probability distributions, allowing us to gain insights into the variations between them. In the context of PPO, KL-Divergence guides the optimization process to maintain consistency between the updated policy and the original policy.
In PPO, the objective is to enhance the agent's policy by continuously adjusting its parameters using the rewards obtained by interacting with the environment. Nevertheless, implementing policy updates too quickly can result in unstable learning or significant policy alterations. In order to tackle this, PPO implements a restriction that hinders the frequency of policy updates. We ensure this constraint by utilizing KL-Divergence and using the original freezed-Instruct LLM model as the reference.
To grasp the concept of KL-Divergence, let's consider two probability distributions: the distribution of the original LLM and a newly proposed distribution of an RL-updated LLM. The KL-Divergence quantifies the information gain obtained by encoding samples from the new proposed policy using the original policy. PPO ensures that the updated policy remains close to the original policy by minimizing the KL-Divergence between the two distributions. This helps prevent any drastic changes that could potentially hinder the learning process.
.png)
Direct Preference Optimization (DPO)
Regulating large unsupervised language models (LMs) is hard. This is true despite their ability to learn and reason. Traditional methods, such as RLHF, involve training a reward model, using human preference labels. The model is then fine-tuned to match these preferences. Applying a reward model and training a strategy to maximize it can lead to instability in RLHF.In 2023, Rafailov et al. at Stanford proposed Direct Preference Optimization (DPO) as a way to streamline and enhance the procedure. DPO shows how a math relationship links optimal policies and reward functions. It can solve the problem of maximizing rewards in a single stage of policy training in RLHF. Policy probabilities transform the RLHF objective using DPO. They let the LM implicitly determine the policy and reward. This invention removes the need for a separate reward model. It also reduces the complexity of RL.DPO uses an approach that streamlines RL by removing the need for two stages: fitting a reward model and training a policy through sampling. DPO simplifies the challenges of maintaining stability during step two. The LLM is trained using a dataset. The dataset includes prompts, worse completions, and better completions. We use a new loss function. It makes better completions more likely and worse ones less likely. This is done by considering the implicit reward model and applying appropriate weights. LLMs serve as reward models, eliminating the need for an additional one. The main advantage is that backpropagation optimizes a straightforward loss function.DPO surpasses traditional methods in terms of stability, performance, and processing efficiency. During fine-tuning, we avoid LM sampling. We also avoid reward model fitting and hyperparameter adjustments. DPO has a classification objective. It aims to maximize the fit between preferences and policies. It does this without using a reward function or reinforcement learning.
.png)
Kahneman-Tversky Optimization (KTO)
In 2023, the research paper titled "Human-Centered Loss Functions (HALOs)." from Stanford and Contextual AI was presented by Ethayarajh et al. from Stanford and Contextual AI. It introduces Kahneman-Tversky Optimization (KTO). KTO is a new method for aligning large language models (LLMs) with human feedback. It is built upon the principles of prospect theory, a theory in behavioral economics. In KTO, we prioritize maximizing LLM generation effectiveness. We do this by including valuable human feedback, not by relying on tradition.
Kahneman-Tversky Optimization (KTO) is a loss function. It prioritizes the value of language model generations and takes a human-centered approach. Policy optimization methods focus on maximizing log-likelihood. Unlike them, KTO aims to maximize utility.
KTO achieves its goal by making the outputs it wants using a utility function. This function effectively trains a language model. This process consists of a few essential steps:
- Utility Function: A utility function is defined using the principles of Kahneman-Tversky's prospect theory. This function assigns a value to each potential output of the language model. The value shows how desirable it is from a human perspective. The utility values can be determined by considering factors such as relevance, coherence, or adherence to specific criteria.
- Output: During training, the language model produces outputs based on provided inputs. The outputs are whole sequences, like sentences or paragraphs, and not single words.
- Evaluation: Every output is assessed using the utility function. The utility score measures the level of desirability or alignment between the output and human preferences or the objectives.
- Optimization: The model's parameters are adjusted to improve the chances of generating outputs with higher utility scores. The optimization process strives to maximize the expected utility of the outputs. This essentially motivates the model to generate better results.
- Iterative Training: Continuously generating outputs, receiving utility evaluations, and updating its parameters. Over time, the model learns to produce outputs. They are more aligned with the utility function's assessment of desirability.
Essentially, KTO changes the focus from conventional training goals. From predicting the next token or matching paired preference data to directly optimizing outputs. These outputs are deemed valuable based on a utility framework. This approach is especially useful in applications where the output quality is subjective. Or, where specific output traits are highly valued.
Advantage of KTO over PPO and DPO
KTO offers simplicity in data collection as, unlike DPO and PPO that require complex paired-preference data, it efficiently operates with simpler binary feedback on outputs. Its practical application in real-world scenarios is enhanced by its less stringent data requirements, making it more suitable where collecting detailed preferences is infeasible. Moreover, KTO's focus on maximizing human utility potentially leads to more user-friendly and ethically aligned outputs.
.png)
RLAIF
In RLHF, collecting high-quality human preference labels remains a significant challenge. We compare RLHF and RL from AI Feedback (RLAIF) in a direct comparison. In this technique, an off-the-shelf LLM labels preferences instead of humans. For instance, in summarization, human evaluators prefer the generations from both RLAIF and RLHF models. They prefer them over a supervised fine-tuned baseline model in about 70% of cases. Also, when asked to compare RLAIF and RLHF summaries, humans show no preference for either one. These findings show that RLAIF can match human performance. Solving the challenge of scalability limits of RLHF.
.png)
Bias Issues in RLHF
The potential biasing issues in RLHF or RLAIF can be there since we are dealing with datasets and any data distribution might have some portion of data values that fall into a similar class. The algorithm can thus produce results that reflect and perpetuate biasedness within the dataset it has been trained and tuned upon.
- There is selection bias in RLHF. It depends on input from human evaluators. They may have their own biases and preferences. So, they may restrict their feedback to topics or situations they can personally connect with. Therefore, the agent may not get to see all of the behaviors and outcomes it will face in the real world.
- Human evaluators too have some bias. They tend to give feedback that fits their expectations. It's not impartial and is based on the agent's performance. This can result in the agent being rewarded for specific behaviors or results. These may not be ideal or preferred in the long term.
- Many human evaluators can have varying opinions. This variation creates inter-rater variability. It arises from their judgments about the quality of the agent's performance. This can result in inconsistent feedback for the agent. This can complicate training for the agent, and can lead to suboptimal performance.
- Human Feedback, being manual, stays limited. The evaluators may not cover all the agent's performance. This creates gaps in learning and may lead to subpar performance in some situations.
To address these issues, selection of diverse evaluator plays a crucial role in reducing bias in feedback. This is done by selecting evaluators with varied backgrounds and perspectives similar to practices in the workplace. Evaluators can be sourced from different demographic groups, regions, or industries. Another effective method to decrease the impact of individual biases and enhance feedback reliability is consensus evaluation. This involves multiple evaluators providing feedback on the same task, creating a sort of 'normalization' in the evaluation.
Calibration of evaluators is also essential; this involves offering evaluators training and guidance on providing feedback, resulting in improved feedback quality and consistency. Additionally, it's important to regularly assess the feedback process, including feedback quality and training effectiveness, to identify and address any existing biases. Regular performance evaluations of the agent on a variety of tasks and in different environments ensure that it isn't overfitting to specific examples and is capable of generalizing to new situations. Lastly, balancing feedback from human evaluators with other feedback sources such as self-play or expert demonstrations can reduce the impact of bias in feedback, thereby improving the overall quality of the training data.
We now stand on the brink of a new era in AI. LLMs have gone from mere text generators. There are now empathetic machines that understand and align with human intent. This journey is both fascinating and critical. Continuous refinement through RLHF and the strategic use of reward models are key in this journey. They ensure AI can serve humanity in better and ethical ways. As we go further into this territory, the talk about AI development and ethics grows more crucial. AI's future will be shaped by innovations like PPO, DPO, and KTO. It promises a world where machines understand not just our words, but our intents and purposes.