Introduction
Imagine you have a personal assistant that can perform every type of action on your behalf on your phone or laptop like sending an email to someone, browsing internet, booking plane tickets and more. We somehow imagined something like this when we saw jarvis in marvel or any other character in movies 👀. But guess what? it is getting real with the rise of Large Language Models (LLM).
LLMs are only limited to generating text, conversation or image generation capabilities and you might have used tools like chatgpt, midjourney or gemini to do your text or image related tasks. The main problem with LLMs is that they can’t perform “ACTIONS” based on the commands given by the user. These models can provide detailed steps to perform a task or take an action but can’t do it by themselves. This is where Large Action Models (LAMs) come into the picture.
In this article, we will cover the fundamentals, working and architecture of large action models. So let’s get started 🚀
What are Large Action Models?
Large Action Models (LAMs) are AI models that can understand and perform tasks by converting human instructions into action. They are similar to how a person performs an action on different apps for their day-to-day work. LAMs are the latest development in the world of AI, and are built on the foundation of Large Language Models (LLMs), extending their capabilities to include action.

LAM vs LLM
As we discussed above, Large Language Models are great at generating text, conversations, images or any other media and they can also give you step-by-step instructions on how to perform a given task or how to solve a given problem. But they can’t perform an actions on their own and user have to follow the steps provided by LLM to reach the goal. On the other hand, LAMs can also perform actions based on the user input or the instructions suggested by LLM on user interfaces of the applications which we use.
LAMs have more real world interactions than LLMs. Here real world interactions means the interaction with different applications, websites, APIs etc. With this advantage, LAMs provides more flexibility and accuracy with task completion. That’s why LAMs are more well suited for handling complex tasks that involves multiple steps and interactions to make the process easy for users. On the other hand, LLMs are well suited to provide information about queries or detailed instructions to do specific task.
LLMs are trained on massive amounts of text data and on the other hand, LAMs work with neuro-symbolic AI (we will learn about it in detail later in blog) which combines traditional symbolic AI ( uses symbols and abstract reasoning to solve problems ) and neural networks. This enables LAMs to not only react but also reason and perform actions. Some LAMs like rabbit ai are also trained on lots of user interface flow data which can be used to understand the user interface while taking action on it.
How LAMs are Different from LLM Agents?
Now you might be wondering that we already have LLM agents then why do we need LAMs? 🤔 You might have seen some examples of LLM agents in my other blogs or somewhere else in which they can make function calls and perform actions same as LAMs.
In simple terms, LLM agents are a combination of tools and chains of LLM calls with some prompt engineering and with this prompts, they can decide which tool they need to use to accomplish a specific task.
There is a limitation while using tools, for example if you want to make an agent which can book tickets for you so you used one famous platform which allows you to book tickets program programmatically using their API but what if any platform don’t have an api and also what if user want to use another platform 🤔? Then you might need to use another tools which allows you to perform actions on website or apps but still they require a well structured response from LLMs to accurately perform these tasks.
So can we say that LAMs are just another LLM agents? 🤔 Well, it is still debatable. There is no documentation defining the proper difference between LAMs and LLM agents but according to my learning LAMs might be more precise and accurate while performing actions because they are trained on a dataset of application flows and architecture so they are made for performing actions with their own reasoning capability. On the other end, the LLM agents are just following the LLM response and deciding the tool that they can use to complete the given task.
So we can say that LAMs are more autonomous than LLM agents.
How does it work?
To understand the structured nature of human-computer interactions within applications LAM uses neuro-symbolic AI. It combines techniques from both neural networks which are inspired by the structure of the brain and symbolic AI technologies which deal with logic and symbols. Neuro-symbolic techniques can help LAMs understand and represent the complex relationships between actions and human intention.
LAMs can perform various tasks without requiring any assistance. The goal based approach makes them more focused and consistent towards following the steps. The human input will be first processed by an LLM and then LLM will provide the steps to perform the action and LAM will perform the action to reach the goal. Note that the LLM I am referring to here is not any external LLM but the reasoning capability of LAM itself.
LAMs performs an action on different applications using the knowledge base of user interfaces. During the training process, LAMs are trained on user interfaces of different applications and websites and their workflows. This type of training process is called Action Model Learning.
Action Model Learning
Action Model Learning is a form of Inductive Reasoning used in Artificial Intelligence where an AI model learns from observation. In action model learning, the model learns how to perform a specific task by observing another model or user doing the same task. It is very similar to human learning too for example, if you want to know how to ride a skateboard then you watch other people doing it and with observations you learn and this is the same way of training the action models where they learn from your actions.
Action model learning uses reasoning about actions instead of trying them. Instead of just memorizing the information, action model learning focuses on teaching the model about cause-and-effect relationship between the action and outcome. For example, model learns that if you click on input element then you can type something.
Once the training is completed, the model makes the predictions about outcomes of a given action and in case of user interfaces, the model can generalize the workflow so that it don’t need to re-learn about new user interface. For example, if you want to order something then you generally go to the website → search food → select items → order food and LAM will follow the same procedure in any user interface given to it by going to the right places and clicking on right buttons.
Pattern Recognition
We always follow a pattern while performing any task and we learn based on these patterns. For example, if you search for a pizza on a food delivery app and you liked the food from one restaurant so now you have made a pattern that if you want to order a pizza then you will order from this restaurant. In the same way, AI models use pattern recognition to find patterns in data using machine learning algorithms.
Pattern recognition is the foundation of large action models. LAMs need to be able to find patterns in various data like text, images or even user interfaces. This allows them to understand the applications around them. It also helps them to extract key information from data. For example, if user says “Book a flight to paris.” then using pattern recognition LAM will find the action as “book” and the location as “paris” and now LAM will use this information to perform an action by accessing the websites or applications to book flights.
Pattern recognition is used in various tasks like Image processing, Image Segmentation, Computer Vision, Seismic analysis, Speech Recognition, Fingerprint Recognition, etc. Pattern recognition usage possibilities are endless.
Neuro-symbolic Programming
Neuro-Symbolic programming is an emerging field in AI which bridges the gap between traditional symbolic AI and neural networks. Let’s understand both separately.
- Symbolic AI: It relies on symbolic representations like icons and knowledge bases. It is very good at reasoning and manipulating these symbols but can struggle with real world data.
- Neural Networks: These are powerful models inspired by the human brain, particularly effective at learning patterns from vast amounts of data. However, they can be difficult to interpret, making it challenging to understand their reasoning process.
Neuro-symbolic programming combines the learning capabilities of neural networks and reasoning power of symbolic AI for more improved decision making. It is used in various domains like natural language understanding, robotics, scientific discovery, etc.
LAMs use neuro-symbolic programming for reasoning to make informed decisions before making an action. Neuro-symbolic programming makes LAMs more interpretable. This is crucial for understanding why a LAM took a specific action, especially in safety-critical situations.
It’s important to know that not every LAM needs to use neuro-symbolic programming for reasoning but it's expected to become more important as LAMs evolve.
LAMs in Market
LAMs are still an area of research and are evolving but still there are some popular LAMs in the market that increased the hype for LAMs. Let’s explore them one by one 🚀!
Rabbit R1
In Jan 2024, an AI startup rabbit launched their first LAM called rabbit r1 and it increased the hype of LAMs and showed the capabilities of LAMs. R1 was developed to take a leap towards an app-free online experience, by introducing an operating system that navigates all of your apps quickly and efficiently so you don't have to.
R1's operating system, rabbit OS, is the first OS ever built on Large Action Model (LAM). LAM first understands the user input and then converts it into actionable steps. rabbit’s LAM learns from the user’s intension and behavior when they use specific apps. During training, it is trained on more than 800 applications ( according to their claim ) where it learns by observing a human performing actions on those applications and tries to mimic the process, even if the interface is changed.
Using this learning technique, it doesn’t need to use any complex APIs to access these applications or platforms. It also gives more portability or flexibility to get the accurate information.
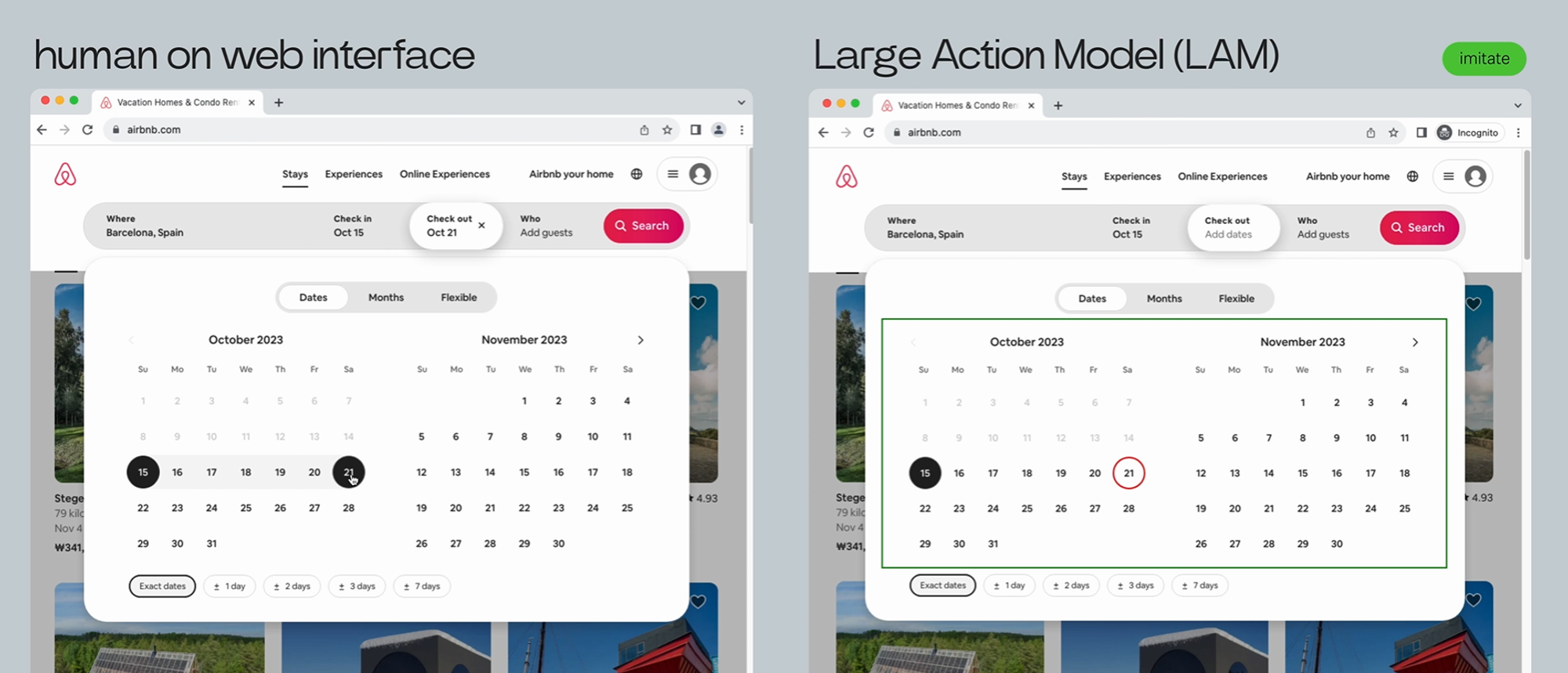
Instead of having black-box model giving actions and adapting to the application during inference, LAM follows a more observable approach. This means that once the application demonstration is provided, a routine directly runs on the application without the need of any observation or thoughts. In other words, LAM tries to understand the feature more than the interface over the time so that even if interface changes in future then it knows the pattern or path it needs to follow to complete certain task.
Rabbit r1 currently supports only 4 applications which are spotify, uber, doordash and midjourney but in future they are going to add support for multiple applications.

R1 uses perplexity AI to get the information from internet and it is one of the reasons for the fast response time of rabbit r1. It also have a vision support which uses computer vision and generative AI to get information about the image or live footage in real time here we are focusing on LAM part so we will not go into much details about it.
With these many features, there are some cons in r1 which needs to be improved:
- The LAM is slow: Even though they introduced the LAM which does the job but it is quite slow for applications like doordash or uber and they have only released 4 application support till now and it is slow then imagine what will happen when they roll out the support for more applications 💀. So the problem might be the training data or with the reasoning capability of the model.
- Not fully autonomous: There are still many features that can be automated like handling brightness or settings needs human interaction. Also it requires some human interaction while using applications like doordash or uber.
With all these pros and cons, we can say that LAMs have a lot of potential but it is still getting started.
Autodroid
Autodroid is an LLM-powered end-to-end mobile task automation system which works as a LAM. It can currently work with only android devices. It uses LLM to generate the instructions and then using app domain knowledge, it performs actions on the applications. It combines the capabilities of LLM and the app-specific knowledge throught dynamic app analysis.
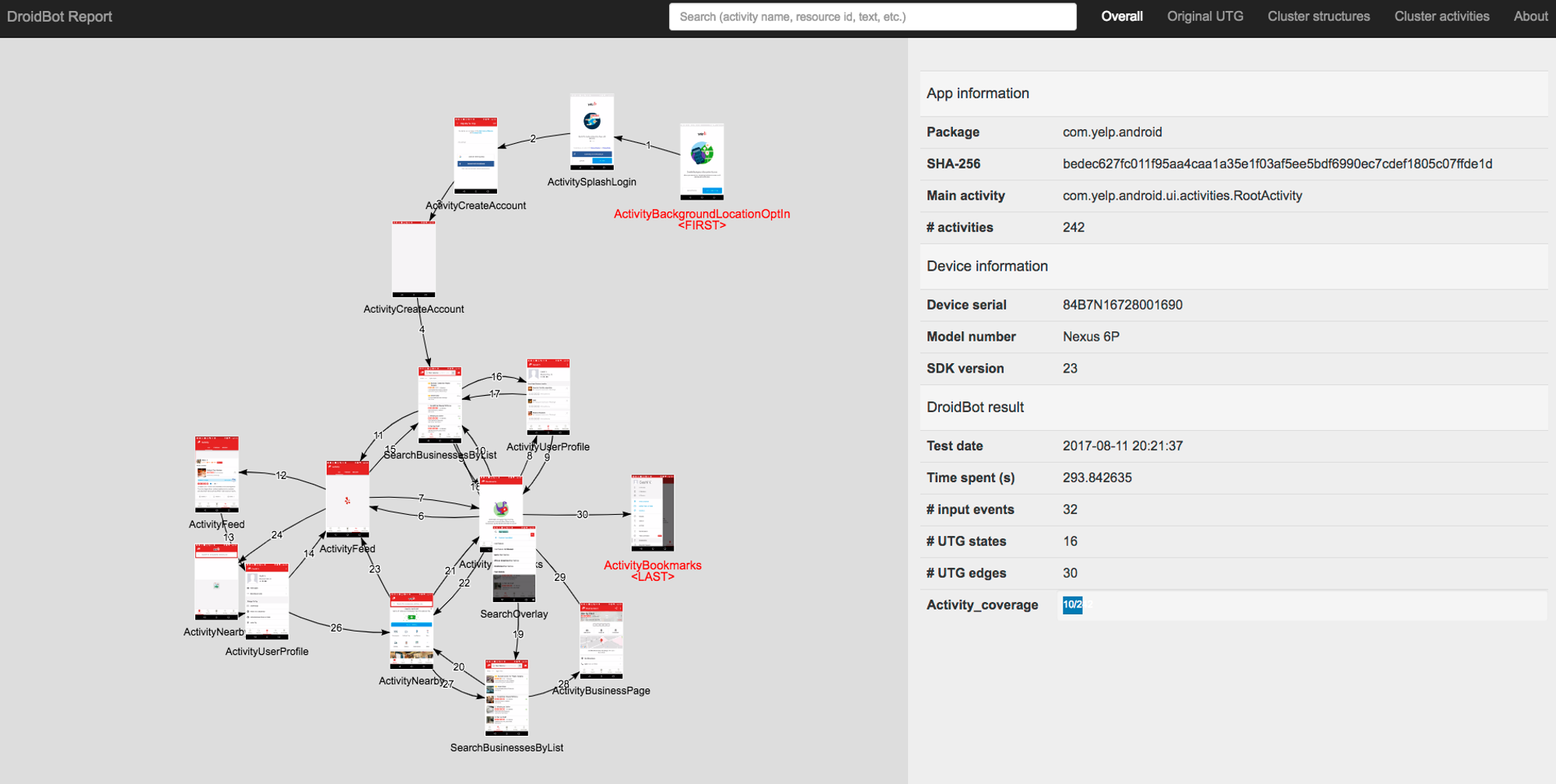
In the offline stage, it obtains app specific knowledge by exploring UI relations and it randomly explores the target apps and extracts UI transition graphs from them. It uses droidbot to generate the UI transition graphs (UTG) for any application. droidbot is a test input generator for android that can send random or scripted events to an android app.
The UI transition graph generated by droidbot looks like this:
The main issue with LLMs is that the input and output of task automators are UI interfaces and LLMs can’t understand that. To help LLMs better understand the GUI information and states, autodroid executes tasks by prompting the LLMs with an HTML-style text representation of GUI and querying for action guidance.
In online stage, autodroid constantly queries the memory-augmented LLMs to get the guidance on the next action. The task gets completed by following the LLM-suggested actions. AutoDroid adopts several techniques to improve the task completion rate and optimize the query cost.
Here is how the full architecture of autodroid looks like:
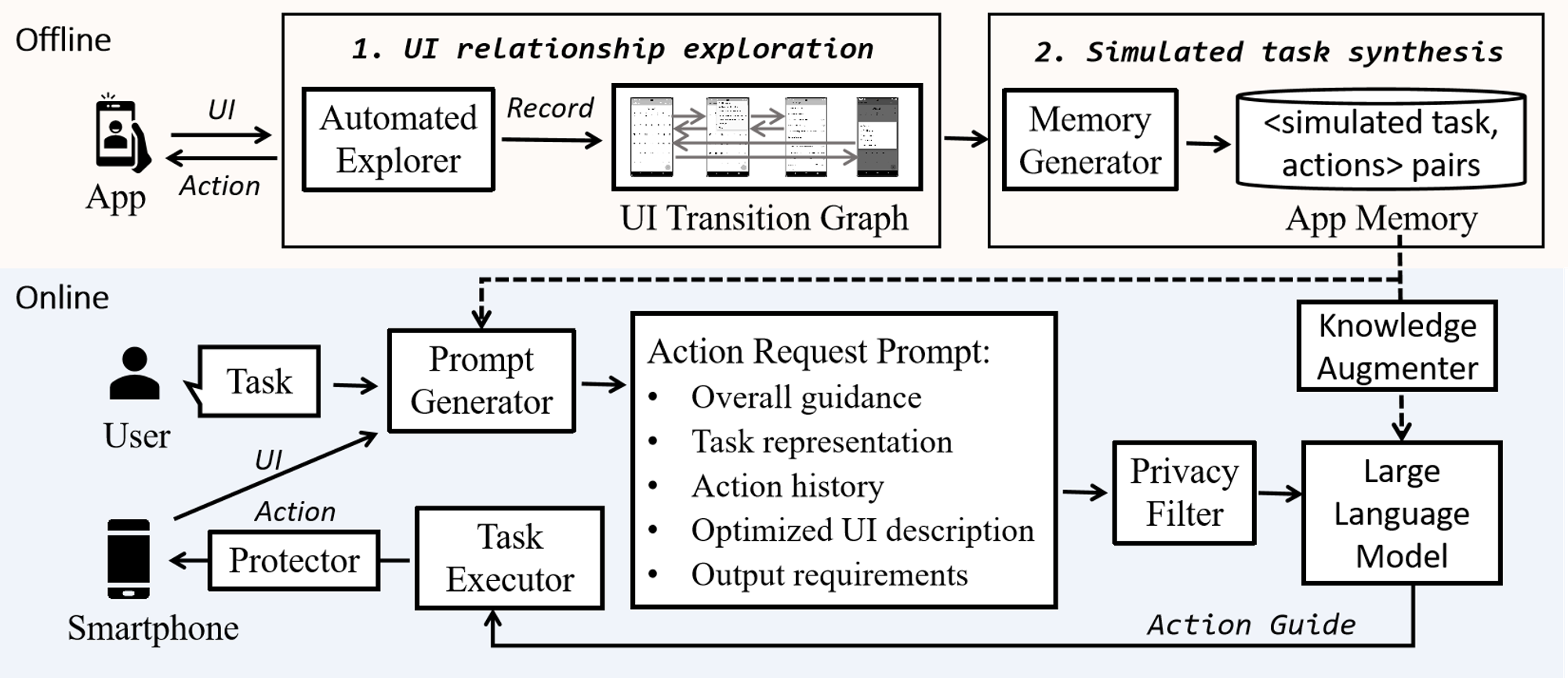
For example, if user says a command like “delete all the events from calendar” then the prompt generator will first generate a prompt based on the task, the UI state description and the information stored in memory. This information includes instructions on how to navigate to the GUI page that contains the “delete events” option. Then the privacy filter will filter out any sensitive information in the prompt for privacy. The filtered prompt is then sent to LLM and then LLM generates the instructions based on the knowledge base it generated in offline mode. Once the LLM provides an answer, the task executor parses the action before performing it on application for safety. If the task looks risky, then it will ask for user confirmation for performing it and then it will perform the action.
The dataset structure of autodroid looks like this:
Let’s understand this structure!
- DroidTask: The top level of the dataset, containing folders for each application included in the DroidTask, such as “applauncher” or “calender”.
- Application Folders: Records all the screenshots and raw view hierarchy parsed by droidbot
- States Folder: This folder contains all the captured states of the application during usage. A state includes both visual representations (screenshots) and structural data (view hierarchies).
- Screenshots: Images captured from the application’s interface while exploring the application
- View Hierarchies: JSON files containing the structure of the application’s UI for each captured state.
- Task Files: YAML files named “task1.yaml”, “task2.yaml” etc containing the data for specific tasks withing the application.
- UTG File: A “utg.yaml” file that contains the UI transition graph information generated by droidbot
- States Folder: This folder contains all the captured states of the application during usage. A state includes both visual representations (screenshots) and structural data (view hierarchies).
Here are some video examples of autodroid running for given tasks 👇


Autodroid is evaluated with a benchmark of 158 manually labeled tasks from 13 open-source mobile applications like calendar, messenger, contacts etc. For each task, they evaluated the effectiveness of autodroid using different LLMs like gpt-3.5 or gpt-4 and here are the evaluation reults:

Still there are some limitations like:
- The current implementation is not good at determining the task completion.
- The task completion instructions might be unstable due to the randomness of LLMs, style/quality of GUI and task descriptions.
Hands-On: Let’s try a LAM
So now we know enough about large action models so it’s time for a quick demo 🤩!
I don’t have rabbit r1 right now ( 🥲 ) so we will try to setup autodroid on our local machine as it is open-source and free to use.
Prerequisites
Before using autodroid, you will need to setup these things in your machine:
- Android SDK - I will suggest you to download android studio because you can also download android emulators from it
- Python
- Java
- OpenAI API Key
- Conda (Optional)
Once you have downloaded everything, go to the path where your sdk is installed, generally it will be in “C:\Users\<Your_Name>\AppData\Local\Android\Sdk”.
In that folder, go to platform-tools folder and copy the current path of that folder and add that path in your environment variables.
The final path will look like this:
And now you can use sdk tools like adb to connect your emulator or android device with your system and this is exactly what we are going to do next 📱
Start your emulator device or connect your phone with USB cable with your machine.
If it is properly connected then you will see your emulator listed in connected devices when you will run “adb devices” command in your terminal.
Installation
First of all, clone the autodroid github repository and install the required packages and dependencies:
Download the list of apks from this link because they have provided different apk files specially trained for specific applications. If you want to use it for different applications, then you can use “Firefox-Android-115.0.apk" file.
At last, add your openai key as an environment variable in “tools.py” file

And we are now ready to run autodroid on our emulator 🚀!
Let’s Get our Hands Dirty
First of all, start your emulator or android device and connect it with your system using adb and verify it using “adb devices” command.
Autodroid accepts these parameters:
- -a: the path of apk file that you want to use
- -o: Output directory
- -task: Explain your task here
Finally, run this command to start an autodroid session!
Here is the video walkthrough of autodroid 👇
Use Cases of LAMs
Large action models have huge potential among businesses in different industries so let’s discuss the different use cases of LAMs for your business or personal use 💡
Business Use Cases
- Improved Customer Support: LAM-powered chatbots can handle different customer query tasks like answering questions, creating support tickets and even resolve simple issues. Imagine a LAM scheduling appointment or solving billing issues all autonomously based on the user query. With LAMs, the customer service chatbot not only understands the query but also takes action to resolve the problem. It can access databases, process information, access internal portals all by itself.
- Improved User Experience: LAMs can personalize user experiences across various platforms. Imagine a virtual assistant that not only do the task for you but learns from your preferences or history and improves itself for better user experience. Imagine saying “Order my favorite friday meal” and LAM already knows your favorite restaurant and meal and orders the food for you 👀. I will personally love this kind of feature 😎.
- Process Automation: LAMs can automate repetitive and complex processes and workflows in your organization for example, task management, stock management or data handling. In my opinion, we don’t even need to do daily check-ins with humans to plan our day-to-day tasks, the LAM agents will do that for you in near future, what do you think about it? 🤔. There are still so many workflows which can be automated using LAMs.
- Personalized Marketing: LAMs can personalize marketing campaigns by understanding customer preferences and behavior. Imagine an LAM creating targeted email campaigns or social media ads based on individual customer data, leading to higher engagement and conversion rates.
- Robot Control and Automation: LAMs can bridge the gap between humans and robots, allowing for natural language-based interaction and control. This can revolutionize manufacturing, logistics, and other sectors where robots play a crucial role.
Future of LAMs
Do you remember that we discussed about jarvis at the start of the blog? We are reaching that level of automation and it will not be an imagination anymore 👀. Imagine you can handle everything on your phone just with a voice or text command and LAM will use your phone on your behalf to perform those tasks. This will also help people with disabilities and non-technical backgrounds to complete their tasks (Imagine LAMs taking input as a sign language using vision).
LAM-based AI assistants are the next big thing in the generative AI field because it will not just manage your calendar but can book tickets, order food, search the internet, take notes and learn from your preferences to improve your user experience.
While still under development, LAMs have lots of potential to automate different kind of workflows in various fields and can be a next revolutionary thing after LLMs. LAMs will also be used in other AI fields like computer vision and robotics for hardware and vision support.
Overall, LAMs hold immense potential to automate workflows across various departments, improving efficiency, reducing human error, and freeing up employees to focus on higher-value tasks.
Conclusion
As we discussed in blog, LAMs have capabilities to perform actions on behalf of user and it is revolutionizing the game of autonomous agents. Whereas we have LLM agents which can do function calls, make api calls based on the LLM response for limited tasks, we will have LAMs that can do reasoning by themselves before taking an action and then will perform action on user interfaces just like a normal human.
The potential applications of LAMs are vast and evolving. As research progresses and technical challenges like latency or reasoning are addressed, LAMs have the potential to become fully autonomous by seamlessly integrating into our daily lives and making human-machine interaction more easy, meaningful and fun.
Need help with AI Agents?
So, if you are looking to automate your email management, hiring, task management or any type of workflow that is repetitive then autonomous agents are a very good consideration to automate your tasks with the use of Artificial Intelligence.
If you are looking to build custom AI agents to automate your workflows then kindly book a call with us and we will be happy to convert your ideas into reality and make your life easy.
Thanks for reading 😄.