
.png)

This guide is effectively exploring and explaining the research paper "Cramming: Training a Language Model on a Single GPU in One Day " by Jonas Geiping et. al. The paper explores the challenge of training a transformer-based language model from scratch on a single consumer GPU within a day. The study revisits various components of the pretraining pipeline and modifies them to optimize for this constrained setting, achieving performance close to BERT. The key focus is on scaling down training processes that traditionally require substantial computational resources, making it feasible for researchers and practitioners with limited hardware to develop competent models.
- The modified model, despite being trained on a single GPU, achieved performance metrics that were close to, and in some cases, surpassed BERT's performance on various GLUE tasks.
- Specific details about the model's architecture, such as the number of layers, size of the hidden layers, and attention heads, were adjusted for optimal performance on limited compute resources.
- The training routines were finely tuned, including batch sizes, learning rates, and epoch numbers, to maximize efficiency and effectiveness within the limited training time.
- The paper also provides a detailed comparison of the model's performance with larger models to highlight the effectiveness of their approach.
The escalating trend towards building increasingly large models has ignited a competitive race, fostering an environment where many researchers and practitioners feel overwhelmed by the prospect of training a language model.
Initially, post the original BERT training on TPUs, it was estimated that achieving comparable results on GPUs might take up to 11 days. However, ongoing improvements, particularly in software, have significantly reduced this time. Although many methods still require full server nodes or TPU slices and are geared towards larger BERT architectures, some research aims to optimize training for settings similar to the original BERT model. For instance, SqueezeBERT was trained using 8 Titan RTX cards over four days. Sellam et al. (2022) pointed out that doubling the original BERT training duration tends to reproduce the initial results more consistently.
The paper discusses the complexities and variations involved in estimating the training duration of BERT. The challenge in defining a specific timeframe is due to diverse hardware and software environments and different efficiency measures. However, an approach to establish an upper limit on the training time is by calculating the total number of low-precision floating point operations (FLOPs) within the available time frame. Although this theoretical peak of FLOPs is not usually achieved in practice, it indicates the maximum budget required for training.

A key point of comparison in The paper is the study by Izsak et al. (2021), who attempted to train BERT within 24 hours using a full server node with 8 V100 GPUs. They used a BERTLARGE architecture variant and implemented several adjustments, such as modified learning rates, larger batch sizes, and optimized sequence handling. This setup is re-evaluated as a crucial benchmark for training BERT with limited resources, approximately 15 times smaller than the original budget.
In summary, the training duration for BERT varies significantly based on the hardware and software environment, with improvements in technology allowing for more efficient training times. While original estimates suggested lengthy training periods, subsequent research has found ways to reduce this significantly, though often with the need for substantial computational resources.
The BERT model, introduced by Devlin and others in 2019, served as a foundational transformer for numerous applications in natural language understanding but already demanded substantial computational resources for training. Subsequent enhancements by Liu and others in 2019 amplified its capabilities, significantly increasing the computational demands.
As these pre-trained models gained popularity for various downstream tasks (as noted by Wolf et.al in 2020), a race ensued among industrial labs to create the largest language model. This race led to training processes that enhanced the performance of these pre-trained language models, requiring immense computational power at the zettaFLOP level (referenced by Raffel and others in 2020, Yang and others in 2020, Zaheer and others in 2021) and later escalating to even more extraordinary yottaFLOP scales (as discussed by Brown et.al in 2020, Black et.al in 2022, Chowdhery et.al in 2022, Rae et.al in 2022).
This begs the question,
What downstream performance can be achieved by when training from scratch with a single GPU for a single day?

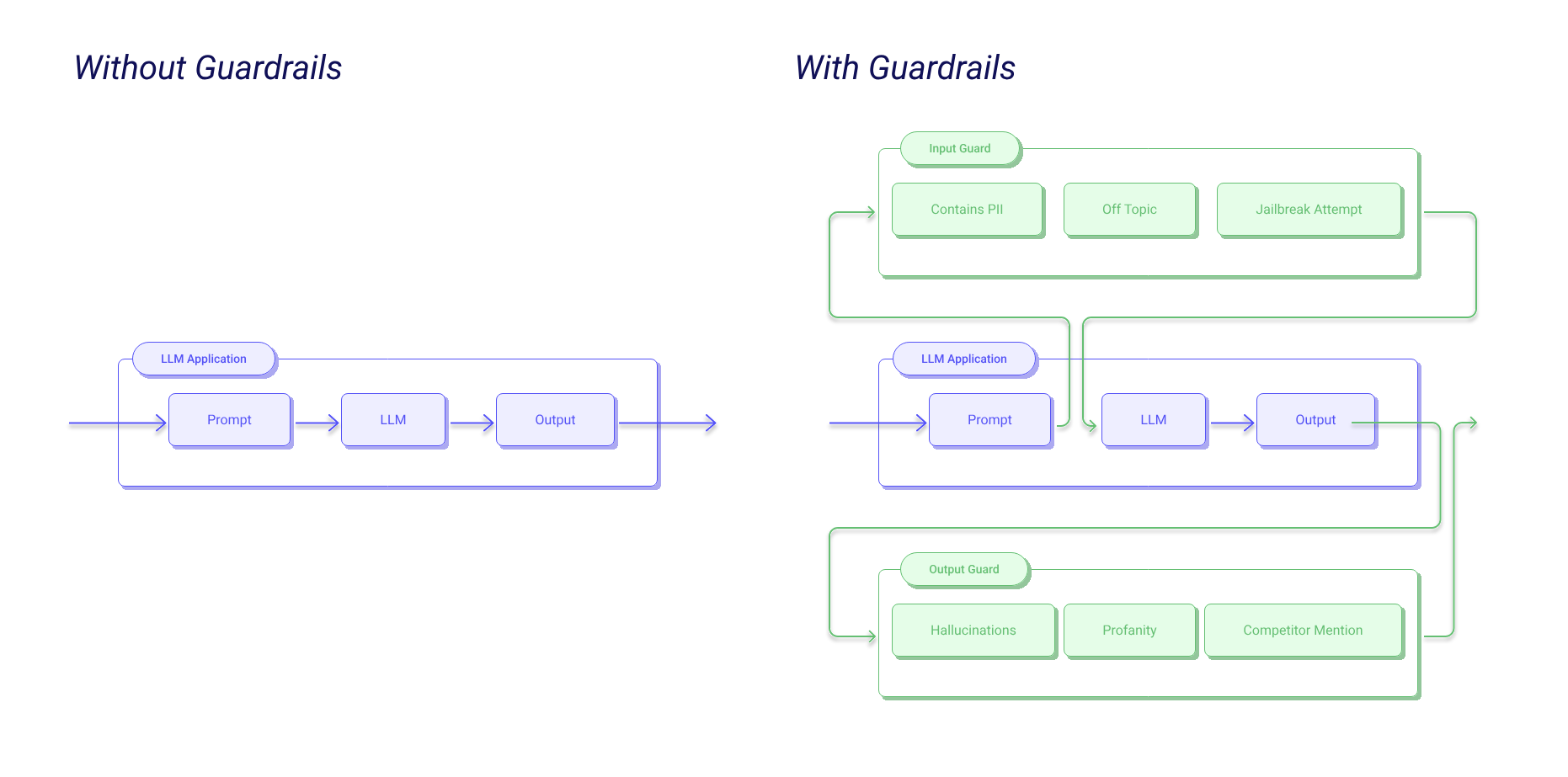
Introduction to Training Language Models on Limited Compute Resources
Training language models on limited computing resources has become an increasingly important topic as the focus on scaling up has led to ground-breaking improvements in natural language processing. However, this has also made it difficult for researchers and practitioners to train language models without access to large-scale resources. In this tutorial, We will explore the concept of training a language model on a single GPU in one day, and investigate the downstream performance achievable with a transformer-based language model trained completely from scratch with masked language modeling.
Training Setup and Limitations
The rules for training a language model on limited compute resources are as follows:
- A transformer-based language model of arbitrary size is trained with masked-language modeling, completely from scratch.
- Existing pre-trained models cannot be included in any part of the pipeline.
- Any raw text (excluding downstream data) can be included for training.
- The downloading and pre-processing of raw data is exempted from the total computing budget.
- Training proceeds on a single GPU for 24 hours.
- Downstream performance is evaluated on GLUE (Wang et al., 2018).
Modifications to the Transformer Architecture for Efficiency
Scaling laws create a strong barrier to scaling down, as per-token efficiency of training depends strongly on model size, but not on transformer shape. Smaller models learn less efficiently, and thislargely mitigates any throughput gains. However, the fact that training efficiency is nearly constant across models of the same size means that They can boost performance by finding architecture modifications that speed up gradient computation while keeping the parameter count nearlyconstant.
Challenges of Scaling Down Training
- Scaling Laws as a Barrier: Scaling laws indicate that model performance is closely tied to its size. Smaller models, while having higher data throughput, learn less efficiently. This creates a barrier in scaling down, as reducing model size doesn't necessarily lead to better efficiency.
- Impact of Model Size Over Shape: It’s found that the size of the model (number of parameters) has a more significant impact on training efficiency than the shape or structure of the model (like the number of layers or heads in a transformer).
2. Architectural Optimization
Attention Block Changes:
- Removing QKV Biases: Simplifies computation without much impact on model size, thereby speeding up the training process.
- Number of Attention Heads: Reducing heads can speed up processing but might affect fine-tuning performance. The balance between head count and performance is maintained.
Feedforward Block Adjustments:
- Disabling Linear Layer Biases: Like with attention blocks, this change is made to accelerate training.
- Incorporation of Gated Linear Units: Offers slight improvements, but unlike some other research, the number of parameters is not increased.
Embedding Layer:
- Use of Scaled Sinusoidal Positional Embeddings: Found to be incrementally better than other embedding techniques.
Layer Structure:
- Preference for Pre-normalization: Helps in stabilizing training and allowing for larger learning rates.
3. Training Setup Modifications
- Masked Language Modeling:
- Increased Masking Rate: A higher rate of 25% is chosen, which fits better with tensor shapes and leads to more efficient training.
- Optimizer Choice:
- AdamW: Chosen for its effectiveness, with specific settings for parameters like weight decay and beta values.
- Learning Rate and Batch Size:
- Customized Schedules: Optimized to suit the training budget and computational constraints.
- Batch Size Adaptations: A progressive increase in batch size during training is employed for efficiency.
- Dropping Dropout:
- Omission During Pretraining: To maximize parameter updates, as overfitting is not a concern in the given training setup.
- Efficiency and Model Size: The findings suggest that while model size optimization offers some gains, they are limited at this scale of compute. Hence, the focus is on architectural and training tweaks to enhance efficiency within the constraints of the model size.
- Utilizing Scaling Laws: Instead of fighting against the scaling laws, the approach involves using them to guide optimizations that can be made without altering the fundamental size of the model.
Data Optimization Strategies
- Bypassing Scaling Laws with Data: While scaling laws limit architectural improvements, they do not restrict enhancements through better data quality. The focus shifts to training on "better tokens" rather than just more tokens.
- Data Filtering and Source Swapping:
- Data Processing: Filtering, sorting, and processing the existing data can lead to improvements.
- Data Source Change: Experimenting with different data sources, including subsets of The Pile and other datasets like C4 and OSCAR.
2. Experiments with Different Data Sources
- Testing Various Datasets: Different sources are tested, including subsets of The Pile, C4, and OSCAR.
- Tokenization: Each data source has its own WordPiece tokenizer regenerated for consistency.
3. Data Processing Techniques
- Deduplication: Attempting to remove duplicate data, but finding it doesn't reliably improve performance.
- Filtering Incompressible Data: Removing data that cannot be compressed efficiently, using a set threshold to decide what to drop.
- Sorting by Sentence Length: Reordering tokenized sequences to have shorter sentences processed first, which showed empirical benefits.
4. Findings and Decisions
- Best Data Source: The natural split of The Pile performed best in terms of downstream GLUE performance.
- Improvements through Post-Processing: Noticeable improvements were achieved through filtering and sorting, leading to a 2% improvement over the original dataset.
- Selection of New Dataset: The Pile, with filtering and sorting, is chosen as the new dataset moving forward.
5. Vocabulary Size Optimization
- Evaluating Vocabulary Size: Finding out whether the original vocabulary size of 30,522 is optimal in the crammed training regime.
- Balancing Vocabulary Size: A smaller vocabulary means fewer unique tokens and relationships to learn, but a larger vocabulary compresses data more, potentially allowing more information in a fixed number of tokens.
- Results: Larger vocabulary sizes correlate with higher average GLUE scores. However, for the MNLI task, the effect plateaus around the original vocabulary size of 32,768.
- Decision on Vocabulary Size: The original vocabulary size of 32,768 is retained moving forward.
The authors provide evidence that even in this constrained setting, performance closely follows scaling laws observed in large-compute settings. They categorize a range of recent improvements to training and architecture and discuss their merit and practical applicability (or lack thereof) for the limited computing setting.
To replicate the experiment, the following steps can be taken:
- Prepare the dataset: Download the raw text data and preprocess it using the WordPiece tokenizer. You can use the preprocessing script provided in the research paper.
- Modify the architecture: Implement the modifications to the transformer architecture for efficiency, such as Pre-normalization, sparse activations, and Layer Norm ε = 10−6.
- Optimize the training routine: Implement the optimizations to the training routine, such as using a learning rate schedule that is tied to your budget, and the learning rate decays as the budget reduces to zero.
- Train the language model: Train the language model on the preprocessed dataset using the modified architecture and optimized training routine. The training should becompleted within 24 hours on a single GPU.
Performance Evaluation and Comparisons
We evaluated the performance of our models on the GLUE benchmark, except for WNLI, following previous studies. They only used MNLI (m) earlier and didn't adjust hyperparameters based on overall GLUE scores. Both the models and the original BERT-base were fine-tuned under the same conditions, with fixed hyperparameters for all tasks and a maximum training duration of 5 epochs. For BERT-base, They used a batch size of 32 and a learning rate of 2 × 10^−5 for 5 epochs. However, for our 'crammed' models, better results were achieved with a batch size of 16 and a learning rate of 4 × 10^−5 with cosine decay.
We compared the performance of the original BERT-base, a recreated BERT training, a setup from a previous study (Izsak et al., 2021), and our modified method. The crammed models performed well, particularly on larger datasets. They also showed substantial improvement over both limited-budget BERT training and the Izsak et al. recipe. The latter performed poorly due to hardware limitations in our tests.
The crammed models were effective even for smaller datasets. The biggest difference was seen with CoLA, a linguistic acceptability corpus. They propose two hypotheses for this, related to the mismatch of our chosen hyperparameters for CoLA. They presented performance data, including average scores excluding CoLA and full average GLUE scores.
The ablation study examines the importance of various improvements in the development of the crammed BERT model. The study involves altering one aspect of the final model—either training, architecture, or data modifications—to the original BERT setup and observing the impact.
The key findings from this ablation study are:
- Co-dependence of Training and Architecture Modifications: Changes in training and architecture must be implemented together. Reverting either to the original BERT setup leads to a failure, indicating that the success of the crammed model relies on the synergy between training and architecture modifications.
- Minimal Training Modifications: A scenario with minimal training changes is also tested. These changes include disabling dropout, implementing cosine decay to zero within the budget with warmup, and using a fixed batch size of 8192. This setup tests how minimal deviations in the training approach affect the model's performance.
- Minimal Architecture Modifications: The study also includes a case with minimal changes to the architecture. This involves using pre-normalization, implementing sparse activations, and setting the Layer Normalization ε (epsilon) value to 10^-6.
Overall, the study highlights that both training and architectural modifications are critical to the success of the crammed BERT model. It underscores the need for a balanced and integrated approach where both aspects are modified in tandem for optimal performance.
Ablation study from the paper highlighting which improvements were most important
The discussion on CoLA (Corpus of Linguistic Acceptability) performance in your text focuses on how sensitive it is to hyperparameter adjustments. Various studies have approached training for CoLA differently, with some opting for longer training times (Jiao et al., 2020) and others for shorter durations (Joshi et al., 2020). Despite these differences, a set of global hyperparameters for BERT does exist, suggesting that the issues with CoLA performance might be due to limitations in the crammed model.
- Hyperparameter Sensitivity: The performance on CoLA is particularly sensitive to hyperparameters. This suggests that the crammed model might have deficiencies, especially in handling tasks like linguistic acceptability.
- Need for More Text Processing: The improvements seen across different GPU setups imply that models might need to process more text before they can effectively memorize and perform well on CoLA. This is in contrast to findings by Liu et al. (2021d), who observed that CoLA is learned relatively quickly compared to other tasks.
Additionally, it is noted that deficiencies in CoLA performance are also common in approaches where BERT is distilled into smaller architectures, as these might have limited capacity for linguistic acceptability.
In the ablation study, the effects of changes in architecture, training, and data are examined. The study finds that minimal modifications are necessary in any case. For instance, architectural modifications like PreNorm layer structures allow for a more aggressive learning rate as described in the training setup. Without both the architectural and training modifications, the training either fails or results in a model with near-random performance.
The ablation study also includes cases with minimal training modifications (dropout disabled, cosine decay to zero within budget with warmup, fixed batch size of 8192) and minimal architecture modifications (Pre-normalization, sparse activations, Layer Norm ε = 10^−6). Comparing these variants, it was found that architectural changes, data changes, or training modifications each contributed approximately two percentage points to the average GLUE score improvement.

Learning rate schedules are strategies to adjust the step size in optimization algorithms like gradient descent during training. The goal is to find the best step size at each stage of the training process. Even though different schedules might seem to behave similarly overall, there are subtle differences, especially noticeable when looking closely.
The image in the middle zooms in on these differences. On the right side, the step sizes set by each schedule are displayed. Schedules like triangular and trapezoidal one-cycle are notable because they tend to perform better towards the end of training. This improved performance might be due to their rapid reduction in step size and the overall larger steps they take during the training process.
Conclusion
This article explores the potential performance of transformer-based language models when they are adapted to environments with extremely limited computational resources. It reveals that incorporating various modifications can yield amazing results on benchmarks like GLUE. However, the process of adapting these models to such constrained settings is challenging. The findings align with those of Kaplan et al. (2020), highlighting that the benefits gained from larger models are often offset by their reduced speed. Additionally, the impact of varying the architecture types and shapes of transformers is relatively minimal in these resource-limited scenarios.

{kind=link}