.png)
The advent of Stable Diffusion models has marked a transformative period in the field of generative AI. From offering unprecedented capabilities in generating detailed and diverse images from textual descriptions. This technology has captivated artists and creators. It has also opened new paths for research and development in many areas. By utilizing Hugging Face's diffusers library, accessing and leveraging the power of Stable Diffusion becomes accessible to a wider audience.
This guide is crafted for:
- Innovators in technology and business exploring AI-driven solutions.
- Creative minds seeking to push the boundaries of digital art.
- Researchers delving into AI's evolving landscape.
Whether you're looking to enhance digital experiences, explore the intersection of art and AI, or understand the underpinnings of generative models, this post will navigate you through building and leveraging Stable Diffusion with Hugging Face libraries, offering a window into the future of AI-driven creativity.
The Essence of Stable Diffusion
Stable Diffusion is a type of AI called diffusion models. They create images by refining a random noise distribution. The refinement continues until the noise becomes a coherent image that matches a given description. These models stand out for their ability to produce high-quality, detailed images across a wide range of styles and subjects.
Stable Diffusion uses the principles of Latent Diffusion to convert textual descriptions into detailed images. This model is a big advance in AI. It's especially so in generative art and content creation. It does this by using a unique mix of technologies and methods.
Understanding “Diffusion” Models
At their core, diffusion models have two main phases: first is the forward process (noising). Second is the reverse process (denoising). During the forward process, the model gradually adds noise to an original image until it is transformed into pure noise. The reverse process is where the magic happens. It works to remove this random noise from an image. It is guided by a textual prompt.
Considering the mechanics of Stable Diffusion, it's crucial to discuss its operation in both pixel space and latent space. Unlike traditional models that directly manipulate pixel space, Stable Diffusion introduces an innovative approach by leveraging latent space. This method significantly reduces computational demands, allowing for the efficient generation of high-resolution images without compromising on detail or quality.
Pixel Space vs. Latent Space: A Comparative Insight
- Pixel Space Models: Operate directly on the image pixels, offering precise control over each pixel for accuracy in image generation. A noteworthy example is the Deep Fluid model released by Stability AI, which excels in pixel-by-pixel image creation. While offering enhanced accuracy and reduced artifacts in generated images—such as seamlessly integrating elements in a kitchen scene without the common issue of objects merging unnaturally—it demands higher computational resources.
- Latent Space Models: By contrast, latent space models, like Stable Diffusion, compress data into a lower-dimensional representation before generating images. This approach not only speeds up the process but also maintains a high level of detail, making it ideal for creating diverse and complex images efficiently.
For a deeper dive into diffusion models and their underlying mechanisms, our previous blog post, "Beginner’s Guide to Diffusion Models and Generative AI", offers a comprehensive overview. It's a great resource for those looking to understand the foundational concepts behind these transformative models.
Stable Diffusion: Architecture and Components
Stable Diffusion specifically leverages a unique architecture that combines several key components:
- Latent Diffusion Models (LDMs): Unlike traditional diffusion models that operate directly on pixel space, Stable Diffusion uses a latent space representation, reducing computational requirements and allowing efficient generation of high-resolution images.
- Variational Autoencoder (VAE): A VAE is used to encode images into a latent space and decode them back to image space. Thereby, facilitating the model's operation in a more compressed and computationally efficient manner.
- CLIP (Contrastive Language–Image Pre-training): Stable Diffusion utilizes the CLIP model to understand and interpret the textual prompts. Thus enabling the generation of images that closely align with the given descriptions.
- U-Net Architecture: The core of the model's denoising process is based on a UNet architecture. UNet is a type of convolutional neural network that excels in image segmentation tasks. This architecture is crucial for the model's ability to refine and generate detailed images.
Latent Diffusion Models (LDMs)
Latent Diffusion Models (LDMs) represent an innovative approach within the broader category of diffusion models, focusing on generating or manipulating data in a latent space rather than directly in the data's original space (such as pixel space for images). This concept is a bit distinct from the U-Net architecture itself but is closely related because of how these elements are utilized within the Stable Diffusion framework.
.png)
The core idea behind Latent Diffusion Models is to apply the diffusion process to a compressed, latent representation of the data. This approach has several advantages:
- Computational Efficiency: By working in a lower-dimensional latent space, LDMs reduce the computational load significantly, making the process faster and more resource-efficient, especially important for high-resolution images.
- Quality Preservation: Operating in latent space allows the model to focus on essential data features, often leading to better preservation of details and overall image quality upon reconstruction.
How Latent Diffusion Works
- Compression to Latent Space: Initially, data (e.g., an image) is compressed into a latent space representation using an encoder, such as a Variational Autoencoder (VAE). This latent representation captures the essential features of the image but in a much more compact form.
- Diffusion Process in Latent Space: The diffusion process then occurs in this latent space. It involves gradually adding noise to the latent representation over a series of steps (forward process) and then learning to reverse this process (reverse process) to recover the noise-free latent representation, guided by a conditioning input, such as a text description.
- Reconstruction from Latent Space: Finally, the denoised latent representation is transformed back into the original data space (e.g., pixels for an image) using a decoder, resulting in the generated or manipulated image.
Variational Autoencoder (VAE)
A Variational Autoencoder (VAE) is a type of neural network that learns to encode data (in this case, images) into a lower-dimensional latent space and then decode it back to the original data space. The process of encoding reduces the data to its most critical features in a compressed form, while decoding attempts to reconstruct the data from this compressed representation.
.png)
At its core, a VAE consists of two main components: an encoder and a decoder. The encoder maps input data (e.g., images) to a distribution in latent space, while the decoder attempts to reconstruct the original input from samples drawn from this latent space distribution.
Encoder
The encoder in a VAE, often a deep neural network, takes input data and outputs parameters of a probability distribution in the latent space, typically a Gaussian distribution. This means instead of directly outputting a fixed vector as in a standard autoencoder, the VAE's encoder outputs parameters (mean and variance) defining a distribution over possible latent vectors.
Mathematically, if x is an input, the encoder produces parameters μ(x) and σ2(x), where the latent vector z is sampled as:
z∼N(μ(x),σ2(x)I)
Decoder
The decoder part of a VAE takes a sampled latent vector z and attempts to reconstruct the input data. The goal is to minimize the reconstruction loss, which is often measured by how well the decoder can reconstruct the input data from the latent vector.
Variational Aspect
The "variational" aspect of VAEs comes into play during the training process. The objective function of a VAE includes two terms:
- Reconstruction Loss: This term ensures that the decoded samples match the original inputs, encouraging the decoder to learn an accurate reconstruction of the data.
- KL Divergence: This term acts as a regularizer, enforcing the distribution of the latent vectors to be close to the prior distribution (usually a standard normal distribution N(0,I)). It essentially measures how much information is lost (i.e., the divergence) when using the latent distribution q(z∣x) to represent the prior distribution p(z).
The VAE's loss function can be described as:
L(x)=Reconstruction Loss+β⋅DKL(q(z∣x)∥p(z))
where β is a hyperparameter that balances the two terms.
CLIP (Contrastive Language–Image Pre-training)
CLIP, developed by OpenAI, is a model trained to understand and match images with textual descriptions. It achieves this by learning from a vast dataset of images and their corresponding textual descriptions, allowing it to develop a nuanced understanding of how language relates to visual content.
In Stable Diffusion, CLIP serves two primary purposes:
- Textual Understanding: It interprets the textual prompts provided by users, understanding the content, style, and nuances the generated image should have.
- Guidance: During the image generation process, CLIP helps steer the model toward outputs that align closely with the textual description, ensuring the final image accurately reflects the prompt.
CLIP consists of two main components: a text encoder and an image encoder. These encoders transform text and images into a common embedding space where the similarity between text and image embeddings indicates their relevance to each other.
.png)
CLIP Text Encoder
The text encoder is typically a Transformer-based model that converts textual descriptions into high-dimensional vectors. Given a text input T, the encoder generates a text embedding ET in the shared embedding space:
ET=TextEncoder(T)
CLIP Image Encoder
Similarly, the image encoder, often a Vision Transformer (ViT) or a ResNet architecture, processes images to produce embeddings in the same space. For an image input I, the encoder outputs an image embedding EI:
EI=ImageEncoder(I)
Contrastive Learning Objective
CLIP is trained using a contrastive learning objective, which encourages the model to align the embeddings of matching text-image pairs closer in the embedding space, while pushing non-matching pairs apart. This is typically achieved using a variant of the triplet loss or noise-contrastive estimation.
The similarity between a text embedding ET and an image embedding EI is often measured using the cosine similarity:
similarity(ET,EI)=∥ET∥∥EI∥ET⋅EI
During training, the model is presented with a batch of N image-text pairs, and the objective is to maximize the similarity of corresponding pairs relative to all other pairs in the batch.
The integration of CLIP into Stable Diffusion is a key factor behind the model's ability to produce relevant and contextually accurate images from diverse and complex prompts.
U-Net Architecture
The U-Net architecture is a type of convolutional neural network (CNN) that was initially designed for biomedical image segmentation tasks. Its structure is characterized by a symmetric "U" shape, consisting of a contracting path (encoder) to capture context and a symmetric expanding path (decoder) that enables precise localization.
Illustration of how image segmentation works, [Multi-level dilated residual network for biomedical image segmentation](Multi-level dilated residual network for biomedical image segmentation)
In the realm of Stable Diffusion, the U-Net architecture is employed in the denoising process, where it functions as follows:
- Encoder: During the forward pass, the encoder reduces the dimensions of the input (latent representation of noise), extracting and compressing the image features. This process involves a series of convolutional and pooling layers that downsample the input.
- Decoder: The decoder then works to reconstruct the image from the encoded features, progressively upsampling the features back to the original image dimensions. This is achieved through a series of convolutional and upscaling layers.
The U-Net architecture is particularly effective for Stable Diffusion due to its ability to handle fine details and textures, making it instrumental in generating high-quality images. Its design allows for the efficient flow of information across different layers, ensuring that the model can accurately reconstruct images from the latent space representation.
.png)
The Role of U-Net in Latent Diffusion
In the context of Latent Diffusion Models, the U-Net architecture plays a critical role during the reverse diffusion process. Here’s how:
- U-Net as a Denoiser: The U-Net architecture is employed as the backbone of the denoising model. It takes the noised latent representation as input and learns to predict the noise that was added at each diffusion step. By predicting and subtracting this noise, the model effectively reverses the diffusion process, gradually restoring the original latent representation from the noised version.
- Efficient Information Flow: Thanks to its symmetric and expansive structure, U-Net facilitates efficient information flow across different layers of the network. This design is particularly effective for capturing and utilizing both low-level details and high-level semantic information throughout the denoising process, which is essential for generating high-quality images.
.png)
In summary, while Latent Diffusion operates on the principle of managing data in a compressed, latent form, the U-Net architecture is leveraged as a powerful denoising mechanism within this framework. Together, these technologies enable Stable Diffusion models to generate detailed and accurate images from textual prompts efficiently.
The combination of these components—VAE, CLIP, and U-Net—enables Stable Diffusion models to generate detailed and contextually accurate images from textual descriptions. The VAE compresses and decompresses image data, maintaining high-quality features; CLIP ensures the generated images align with the textual prompts; and the U-Net architecture refines the images, preserving and enhancing details and textures. Together, these components form the backbone of Stable Diffusion's powerful image generation capabilities.
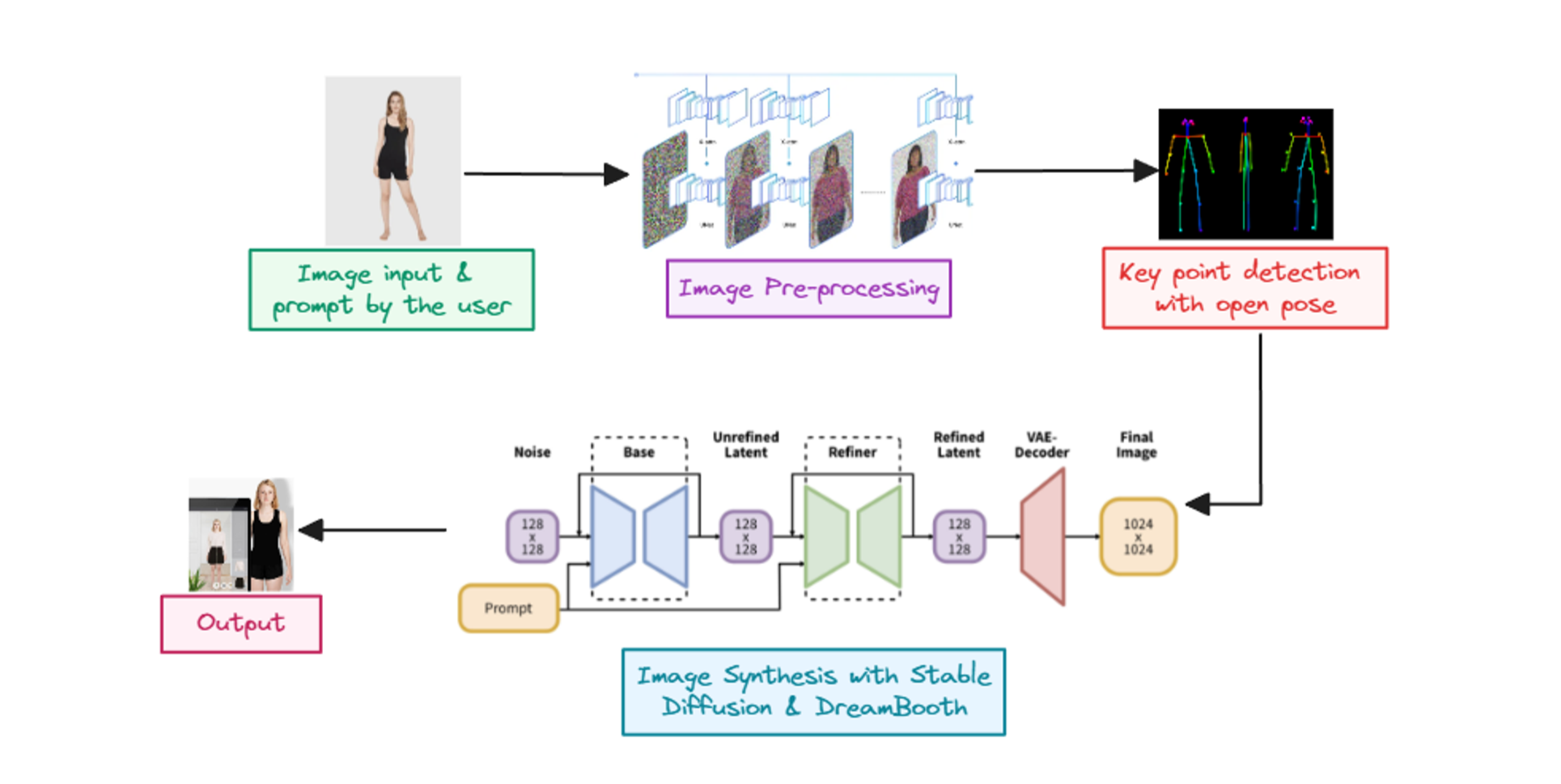
Preparing for Image Generation with Hugging Face
Before diving into the code walkthrough, it's important to grasp the significance of Stable Diffusion and its place within the broader context of generative AI. This technology not only democratizes the creation of art and imagery but also serves as a powerful tool for innovation in areas such as content creation, education, and even scientific visualization.
As we delve into the practical aspects of utilizing Stable Diffusion through the Hugging Face diffusers library, remember that the journey is as much about understanding the underlying technology as it is about creating stunning visuals. Stay tuned for the step-by-step guide that follows, which will equip you with the knowledge to bring your creative visions to life using Stable Diffusion.
Environment Set Up
First, set up your environment with the necessary libraries. If you're using a GPU runtime, this will significantly accelerate the inference process.
Ensure you have a GPU enabled for your runtime to utilize these instructions effectively:
Loading the Stable Diffusion Pipeline
Import the necessary Python libraries and load the Stable Diffusion model. The pipeline simplifies the process of generating images from text inputs:
Move the pipeline to GPU for faster inference:
Image Generation with Custom Prompts
Generate an image by providing a text prompt to the model. For example:
You can adjust parameters like num_inference_steps and guidance_scale to fine-tune the image's fidelity and adherence to the prompt.
Building the Model for Advanced Use
If you wish to customize the diffusion process, you can load and configure each component individually. This approach provides flexibility for experimenting with different configurations and schedulers:
Following the loading of components, you can generate images by manually stepping through the diffusion process, allowing for a deeper understanding and customization of the image generation pipeline.
Real-World Applications of Stable Diffusion
Stable Diffusion's versatility shines across various applications, offering creative solutions from game development to product design. Specifically, its utility in generating VR assets and 3D models for game development has been revolutionary. For instance, leveraging models such as ShapeGF enables the creation of detailed 3D assets, showcasing the potential of diffusion models in virtual reality environments.
Innovative Integration in Diverse Fields
- Game Development: By generating VR assets and 3D models, Stable Diffusion is opening new horizons in immersive gaming experiences. An example includes the generation of realistic car models and environments, enhancing the visual fidelity and engagement of VR games.
- Product Design: In fields like UX/UI design, Stable Diffusion aids designers in rapidly prototyping and visualizing new concepts. This accelerates the design process from concept to final product, showcasing the model's impact on innovation in design.
Conclusion and Next Steps
The journey goes through the architecture and parts of Stable Diffusion. It shows the mix of technologies that power this groundbreaking model. Stable Diffusion shows the advances in generative AI. It leverages the power of VAEs, CLIP's innovative text-image understanding, and the detailed image refinement of the U-Net architecture. This model not only democratizes artistic expression through AI. But, it also paves the way for novel applications in content creation, education, and beyond.
As you embark on your own journey with Stable Diffusion, remember that the potential is limited only by imagination. It is for artists exploring new mediums. It is for developers integrating AI into applications. And, for researchers pushing the boundaries of what's possible. Stable Diffusion offers a canvas for creativity and innovation.
Discover Generative AI with a Personal Touch
Start your journey to innovation with our advanced Generative AI and Diffusion tech. Boost your creative output. Streamline content creation. And revolutionize product design. It's all within reach. The prospect of integrating such transformative AI might appear to be complex. But, we're here to make it accessible.
Connect with us through a call. Wherein I, alongside our CEO, will provide a tailored consulting session to navigate the possibilities Generative AI can offer your business.
Take the first step towards unlocking new potential. Schedule your consultation today. Let's explore how Generative AI can redefine your business with it.